Recurrent Neural Network (RNN)
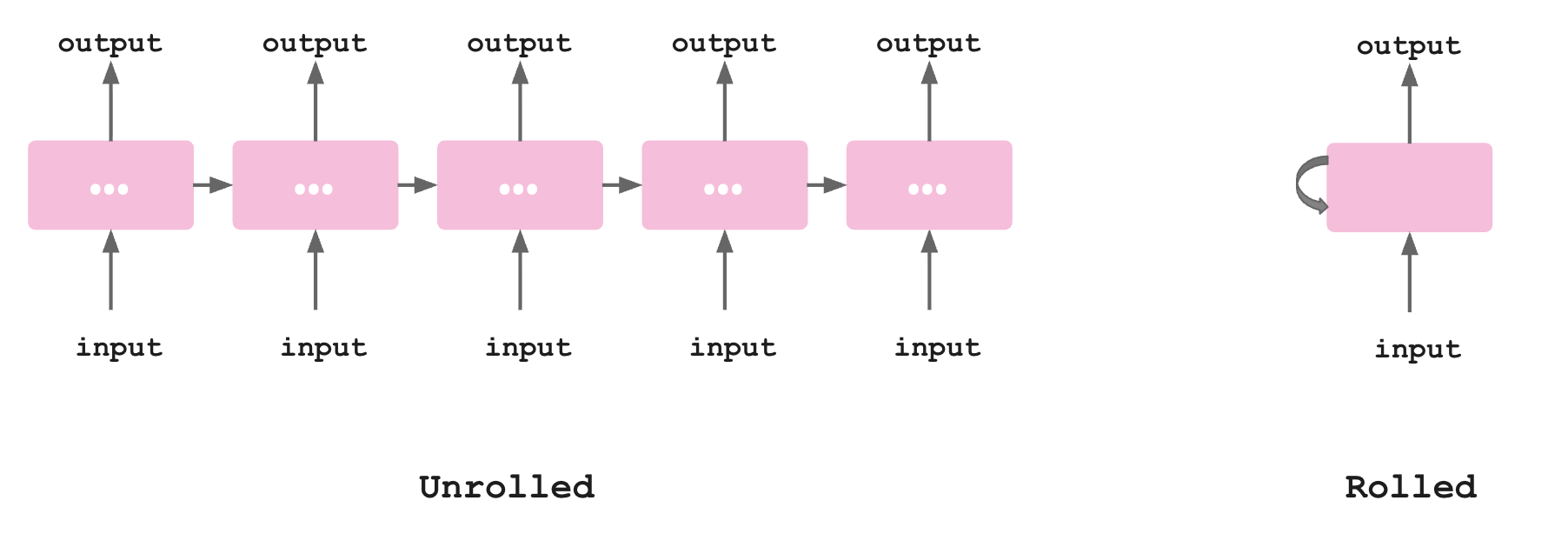
A recurrent neural network has a simple twist: the output of a layer is added to the next input and fed back into the same layer. You can draw this two ways:
- Unrolled — the same block copied left-to-right across time steps, with arrows showing how the hidden state passes forward. This is the more common way to draw an RNN.
- Rolled — a single block with a loop arrow on it, simple and abstract.
The math at each time step:
Where is typically a hyperbolic tangent activation. is the current input (the embedding of the word at position ). is the previous output. are weight matrices. Sometimes the hidden state is denoted if it stays internal rather than being read off as a per-step output.
RNN Cell — click any component to see its role in the equation
Equation
Hover over any part of the diagram to learn what it does.
Components
Hover any part of the RNN cell — the equation highlights the corresponding term and explains its role.
RNN Types
The same RNN components handle a surprising range of tasks depending on how you wire up inputs and outputs:
- Sequence-to-sequence: input at every step, output at every step. Used for stock price forecasting, where each new day produces a new prediction.
- Sequence-to-vector: many inputs, one output. Used for spam classification — read the whole email, output a single yes/no.
- Vector-to-sequence: one input, many outputs. Used for image captioning — encode an image once, then generate a caption word by word.
- Encoder-decoder: one full sequence in (the encoder), one full sequence out (the decoder). Used for machine translation — read the whole French sentence before generating the English.
Sequence-to-Sequence
One RNN output at every input time step. Input and output are aligned — the same length.
Each output is produced at the same time step as its corresponding input.
Task: Stock price forecasting, named entity tagging
"Tag each word: Apple [ORG] is [O] hiring [O] in [O] Berlin [LOC]"
Select an RNN architecture type to see how inputs and outputs are wired, with a real-world task example for each.
You are building a machine translation system that reads a full English sentence and produces a full French sentence. The output length is different from the input length. Which RNN architecture type is most appropriate?