Gated Recurrent Unit (GRU)
The Gated Recurrent Unit (GRU), proposed by Cho et al. in 2014, is a streamlined alternative to the LSTM. It makes two architectural changes:
- The forget and input gates are merged into a single update gate.
- The cell state and hidden state are merged into one — there is only .
The result is a model with fewer parameters, faster training, and often comparable performance to an LSTM — particularly on shorter sequences or smaller datasets.
GRU Cell — Step through each gate
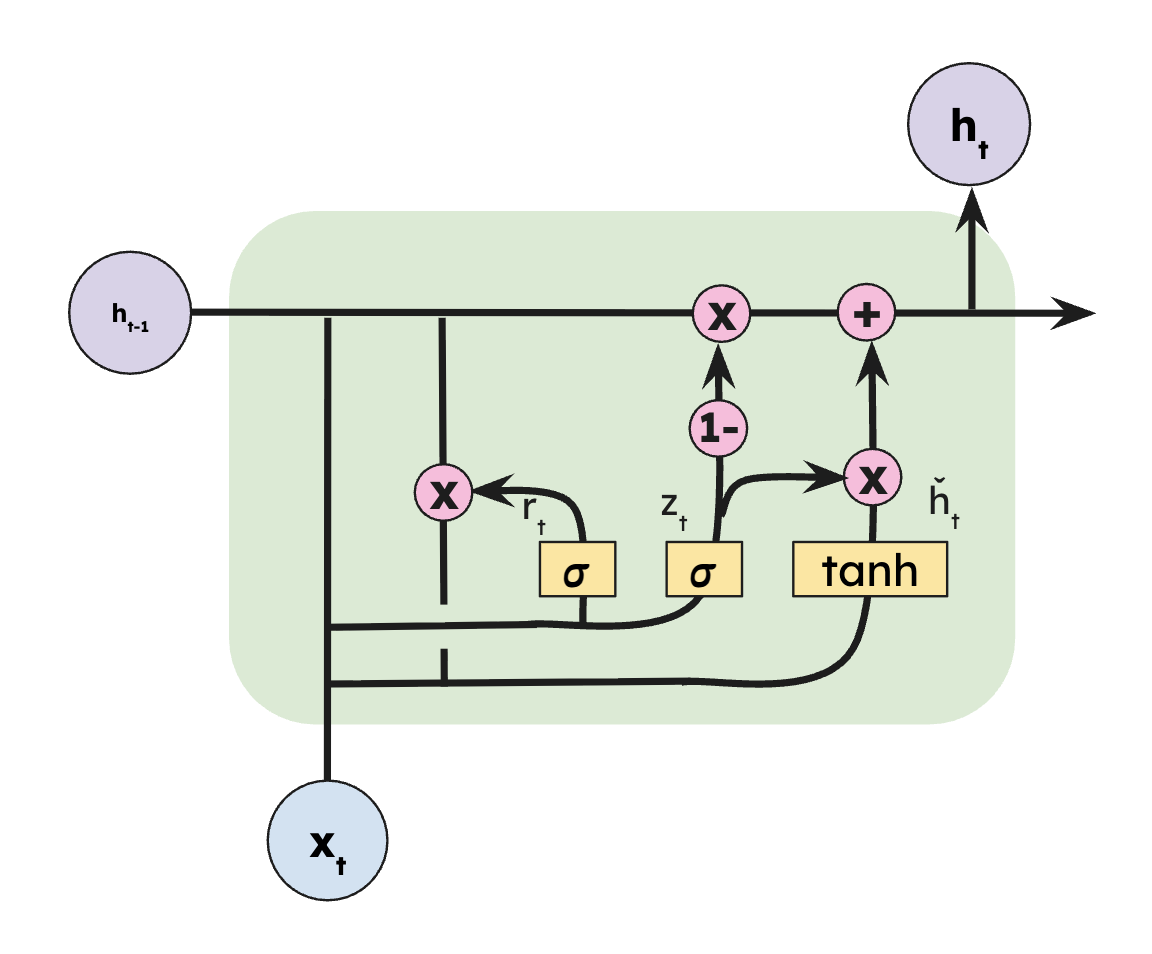
Overview
The GRU simplifies the LSTM by merging the forget and input gates into a single update gate, and collapsing the cell state and hidden state into one.
Two gates — the update gate and the reset gate — control everything. The update gate decides how much of the past to keep; the reset gate controls how much history feeds into the new candidate state. The result is a linear interpolation between old and new that, like the LSTM, is additive and resistant to vanishing gradients. Click each step to zoom in.
Step through each gate to see the highlighted diagram, its equation, and how it fits into the full computation.
LSTM vs. GRU: When to Use Which
GRU tends to be the better starting point when: your dataset is small, sequences are short-to-medium, or you need faster training. Fewer parameters means less overfitting risk and quicker iteration.
LSTM tends to edge ahead when: sequences are very long, the task requires fine-grained control over what to remember and forget at each step, or you have enough data to train the extra parameters.
In practice, try both. The difference is often small enough that dataset quality and hyperparameter tuning matter more than which gated architecture you choose.
In a GRU, what does the update gate z_t do when its value is close to 1?