Long Short-Term Memory (LSTM)
The Long Short-Term Memory network (LSTM), introduced by Hochreiter & Schmidhuber in 1997, was the first architecture to reliably solve the vanishing gradient problem. Its key innovation is a separate cell state — a memory highway that flows horizontally through the cell with only minor, gate-controlled modifications at each step.
Because updates to the cell state are additive rather than multiplicative, gradients flow through many time steps without shrinking. The four gates give the network fine-grained control over what to remember, what to forget, and what to output.
LSTM Cell — Step through each gate
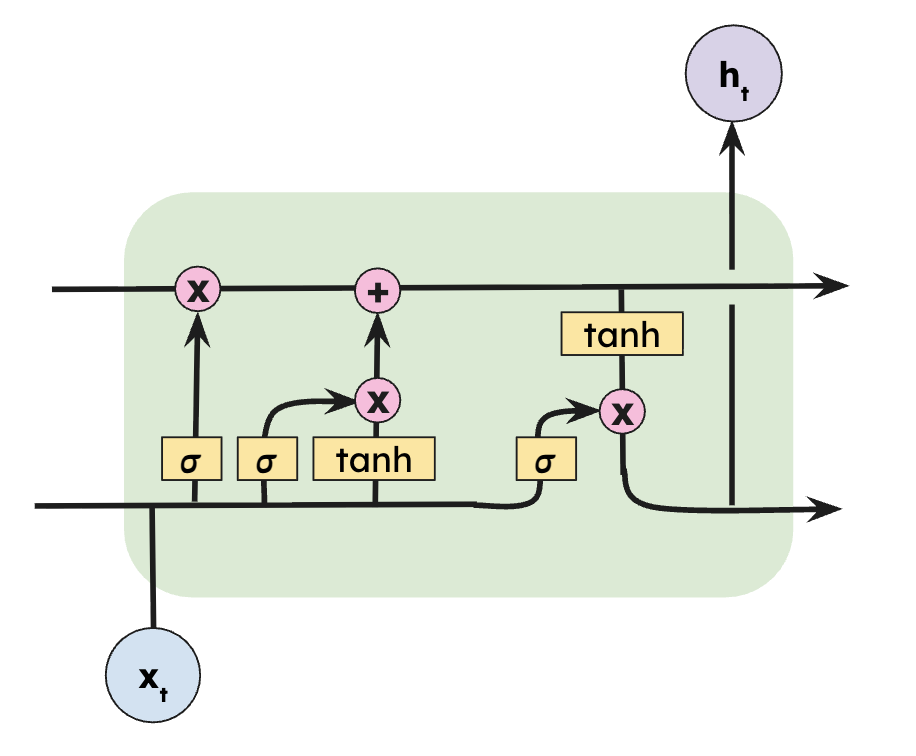
Overview
The LSTM cell solves the vanishing gradient problem through a dedicated cell state — a memory highway that flows through the cell with only minor, gate-controlled changes at each time step.
Four gates work in sequence: the forget gate erases stale memory, the input gate writes new information, the cell state update combines them additively, and the output gate decides what to expose. Click each step to zoom in.
Click any component of the LSTM cell to see its equation and learn what it does. The cell state (green highway) is the key to understanding why LSTMs defeat the vanishing gradient.
Why Does the Additive Update Fix Vanishing Gradients?
When you backpropagate through an unrolled RNN, the gradient of the loss at time T with respect to a hidden state at time t is computed by repeatedly applying the chain rule — once per time step between t and T. At each step, you multiply by the Jacobian of that step's transformation: a matrix that captures how a small change in the hidden state at one time step affects the hidden state at the next. In a vanilla RNN this Jacobian is tied to the same weight matrix at every step. If the largest singular value of that matrix is less than 1, each multiplication shrinks the gradient — and after twenty or fifty steps of multiplying by something less than 1, the gradient is effectively zero. This is the vanishing gradient problem.
The LSTM sidesteps this by giving the gradient an alternative path that avoids repeated multiplication altogether. The cell state update — — contains a + node. The gradient of a sum with respect to either of its inputs is exactly 1, so the gradient flows backward through the + node with no scaling at all. The forget gate does multiply (and can still attenuate when is small), but the network learns to set ≈ 1 for memory slots it wants to preserve — meaning the gradient through those positions stays near 1 across many steps. The key difference from a vanilla RNN is that this gating is learned and selective, not an uncontrolled structural consequence of the architecture.
In an LSTM, which gate is primarily responsible for allowing gradient flow across many time steps without vanishing?