The Vision Transformer (ViT)
For years, researchers tried to apply attention at the pixel level for images. But a 224×224 image has 50,176 pixels!
ViT (An Image Is Worth 16×16 Words) solved this: they chopped the image into 16×16 pixel patches and treated each patch as a token. A 224×224 image becomes a sequence of 196 patches. Each patch gets a linear projection into an embedding. Add positional encodings. Run through a standard transformer encoder.
This worked spectacularly. ViT and its descendants now dominate computer vision benchmarks. The connection to NLP is direct: a ViT encoder is architecturally identical to a BERT encoder, just with different input tokenization.
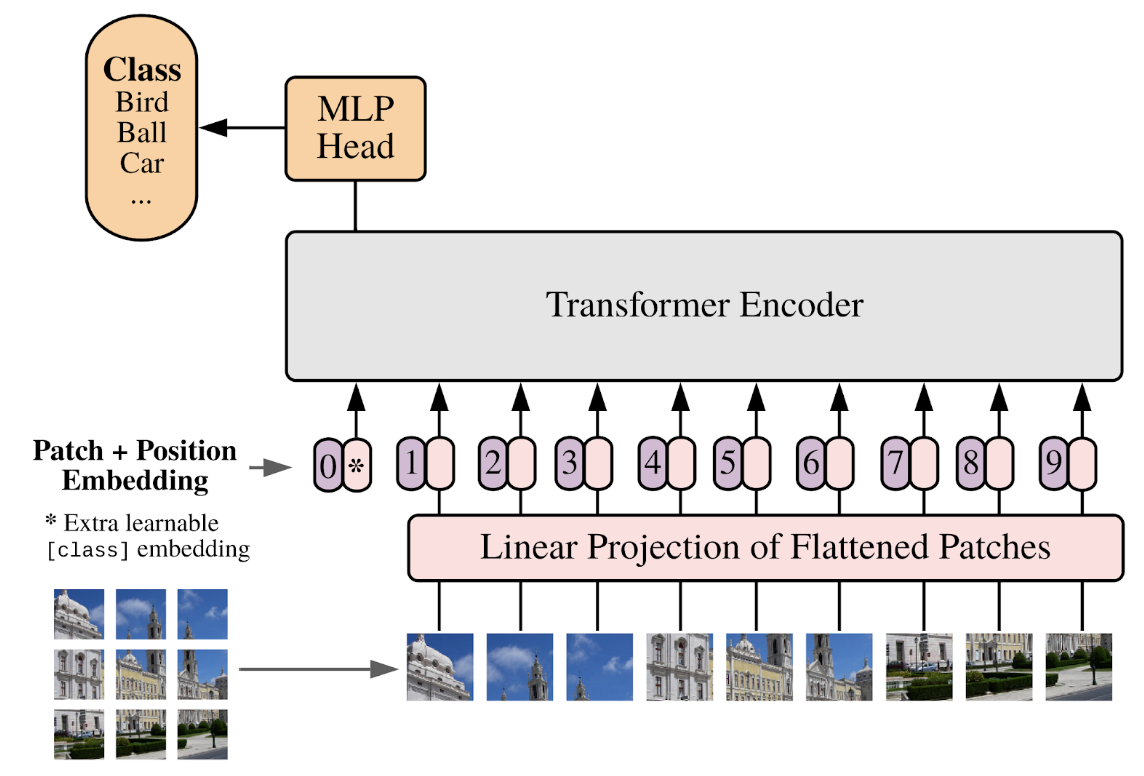
Why Patches Work
The patch-as-token trick works because local image regions carry coherent semantic content — a 16×16 patch of an eye, a wheel, or a leaf is already meaningful. The transformer then uses self-attention to relate patches across the whole image, capturing long-range structure that convolutional networks could only approximate through stacking layers.
ViT requires large training sets to outperform CNNs. On ImageNet alone, a ViT trained from scratch underperforms a ResNet of comparable size. But pretrained on JFT-300M or similar large corpora, ViT dominates. This data-hungry property mirrors BERT: inductive biases (locality, translation equivariance) are helpful when data is scarce, but given enough data, the general-purpose transformer can learn them implicitly.
A 224×224 image is processed by ViT with 16×16 patches. How many patch tokens does the encoder receive (ignoring any CLS token)?