CLIP: Connecting Text and Images
CLIP (Contrastive Language–Image Pretraining, OpenAI 2021) places text and images in the same embedding space using contrastive learning on 400 million (image, caption) pairs scraped from the internet.
Training Procedure
- Encode the image with an image encoder (ResNet or ViT).
- Encode the caption with a text encoder (a transformer).
- Project both into the same dimensional space and L2-normalize.
- Maximize cosine similarity for matched (image, caption) pairs; minimize it for all other pairs in the batch.
- Loss = average of the two directional cross-entropy losses.
What you get: an embedding space where you can search images by text, search text by image, or do zero-shot image classification by encoding candidate class labels as text. CLIP underpins a huge fraction of modern multimodal AI — from image search to text-conditioned image generation to image moderation.
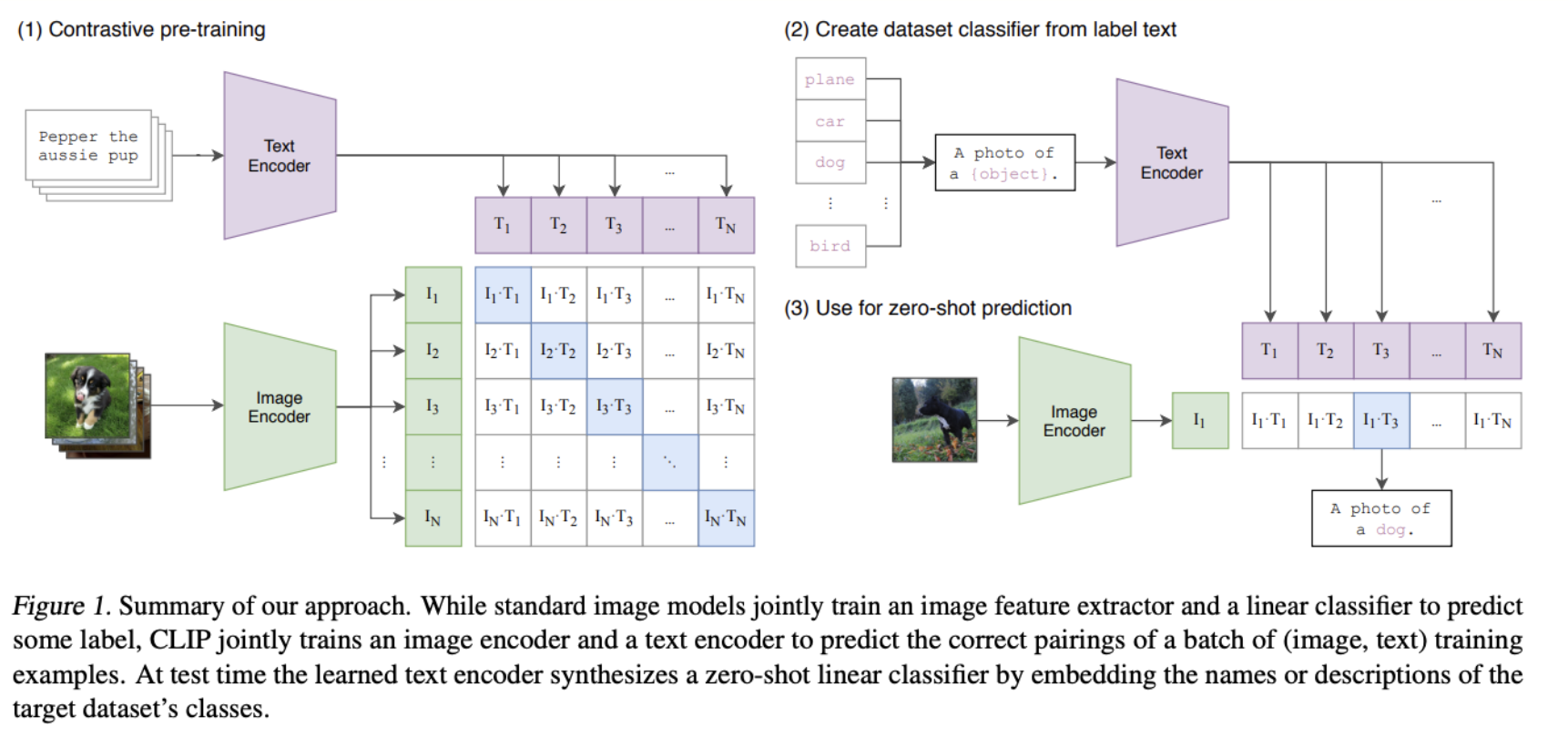
Both encoders run in parallel. The image encoder (ViT or ResNet) and text encoder (transformer) each output a fixed-size vector. Both are projected into the same dimensional space and L2-normalized.
Image Encoder
ViT / ResNet
Input
A golden retriever running on the beach
Image Embedding
dim=512 · L2-normalized
Text Encoder
Transformer
Input
“a dog playing on the beach”
Text Embedding
dim=512 · L2-normalized
Why the same space?
Projecting both modalities into a shared vector space is what makes cross-modal comparison possible. Cosine similarity between an image vector and a text vector is only meaningful if they live in the same space.
Step through CLIP's three-phase training loop: encoding both modalities, building the contrastive similarity matrix, and updating both encoders with the symmetric cross-entropy loss.
Zero-Shot Classification
To classify an image with CLIP, encode the image and a set of text prompts like "a photo of a dog", "a photo of a cat". The class whose text embedding has the highest cosine similarity to the image embedding wins — no fine-tuning required. On ImageNet, CLIP achieves ~76% top-1 accuracy zero-shot, competitive with supervised ResNet-50.
This is a qualitative shift: instead of a fixed label set baked into the model's final layer, CLIP's classifier is defined at inference time by whatever text you provide. New classes cost a sentence, not a training run.
CLIP as Infrastructure
At this point, CLIP and its derivatives are foundational infrastructure for multimodal AI: Stable Diffusion uses a CLIP text encoder to condition image generation. Reverse image search uses CLIP embeddings. Content moderation pipelines use CLIP to detect images matching text descriptions of prohibited content.
CLIP is trained with a contrastive loss on (image, caption) pairs. How does the loss function encourage useful cross-modal embeddings?