Mixture of Experts
In a standard transformer, every parameter is used for every input token. Mixture of Experts (MoE) replaces the dense feed-forward layer in each transformer block with N expert networks plus a router that decides, per token, which expert(s) to activate. Only a small subset of experts fire per token — so model capacity grows without proportional increase in inference compute.
Mixture of Experts is not inherently multimodal, but it is frequently used to scale multimodal models.
How Routing Works
The router is a small learned linear layer. For each token, it computes a score for each expert and selects the top-K (usually K=1 or K=2). Only those experts run; the rest are skipped. The experts' outputs are combined with the router's scores as weights.
The result: a model with 8× or more parameters than a dense model of the same inference cost. Capacity scales cheaply because adding experts doesn't increase the per-token FLOPs — it just gives each token more specialized processing options.
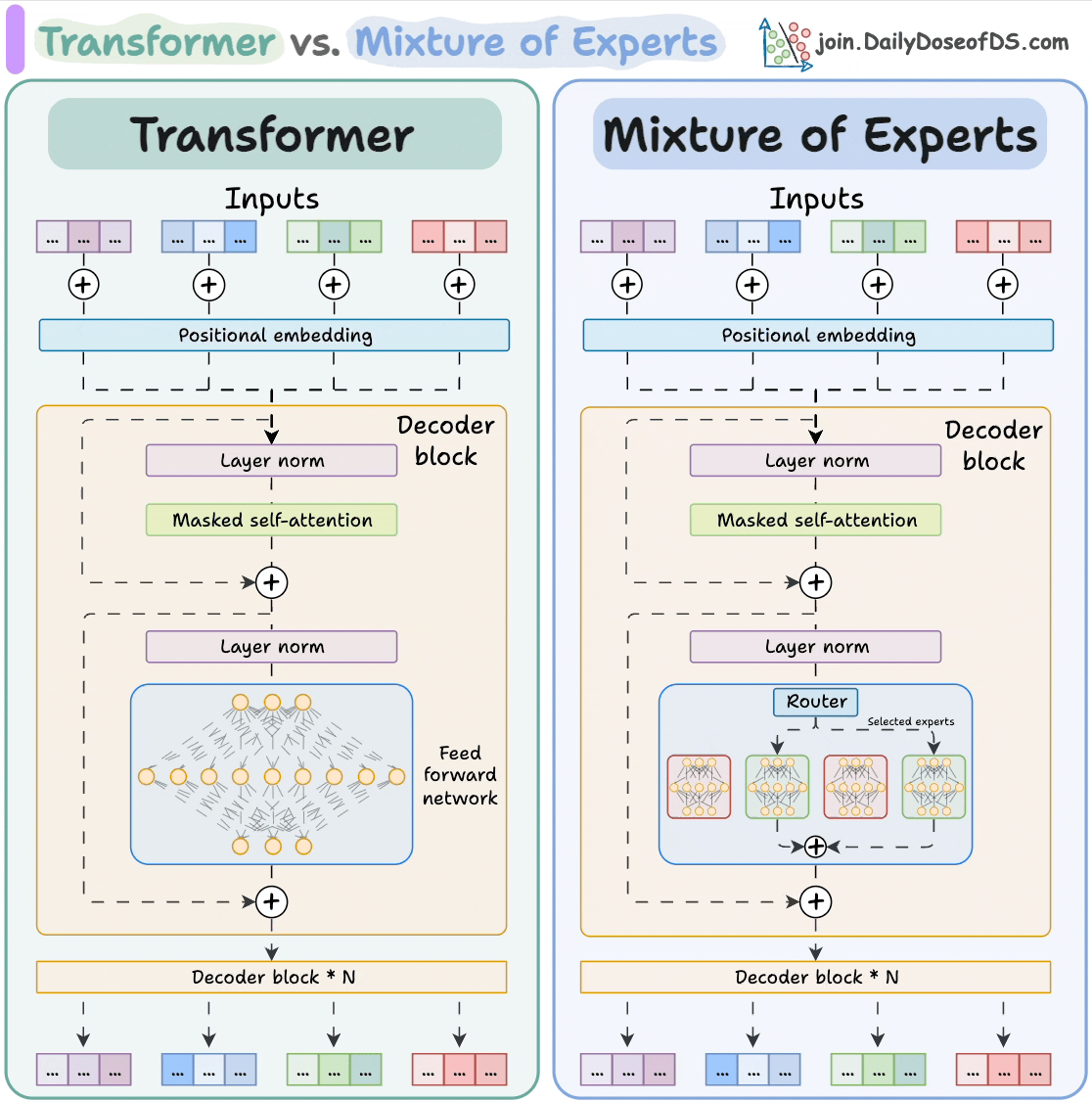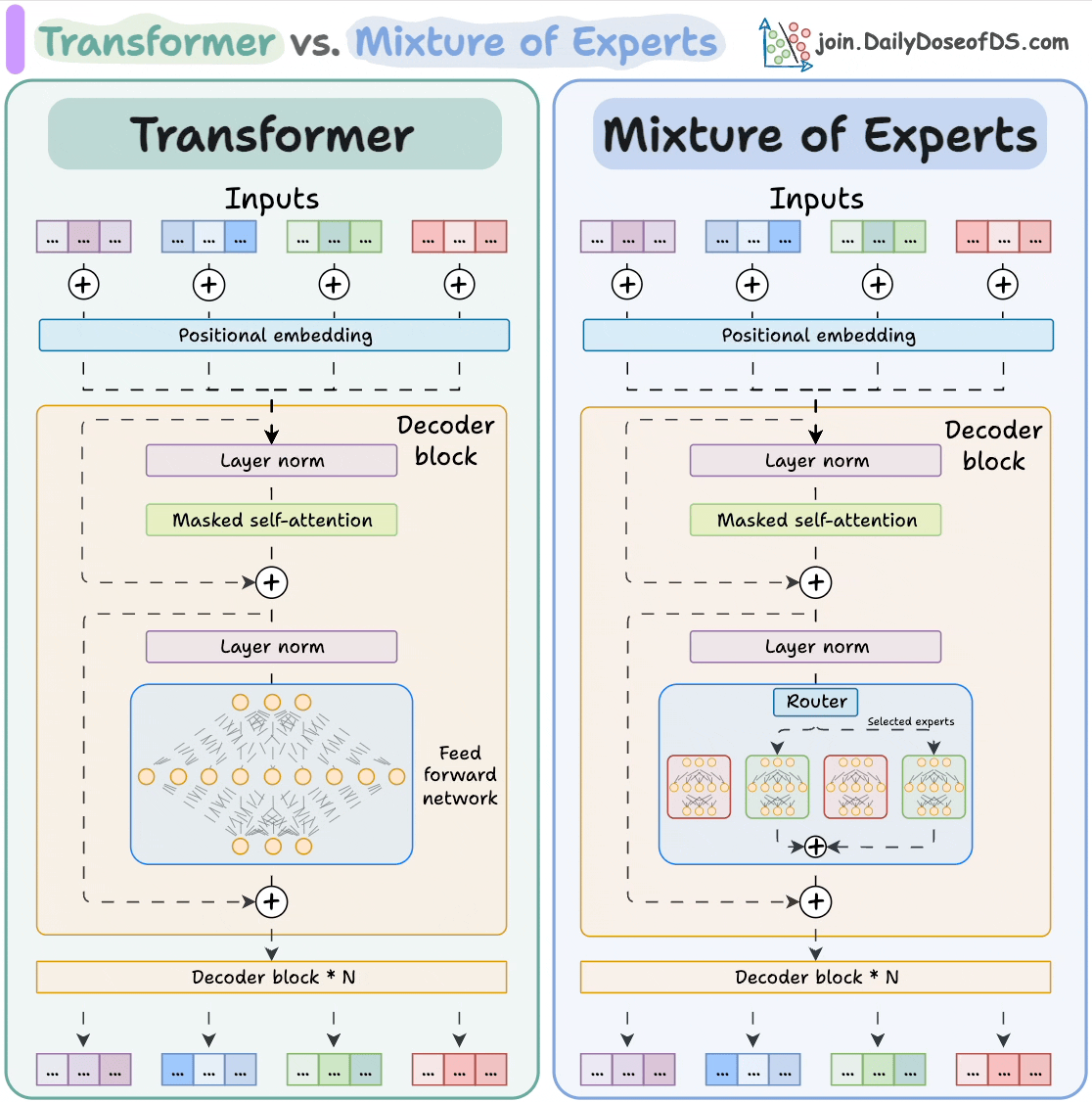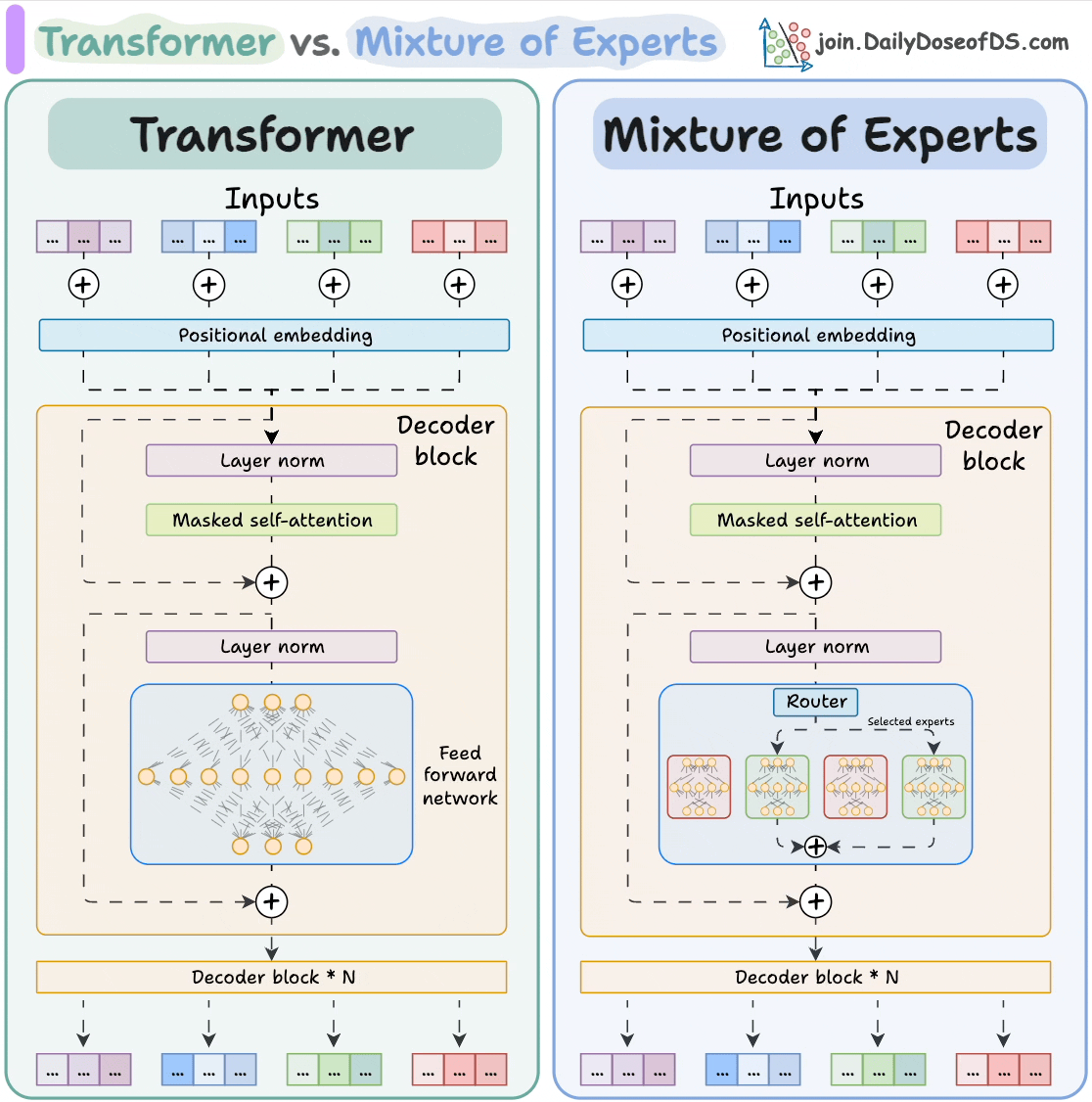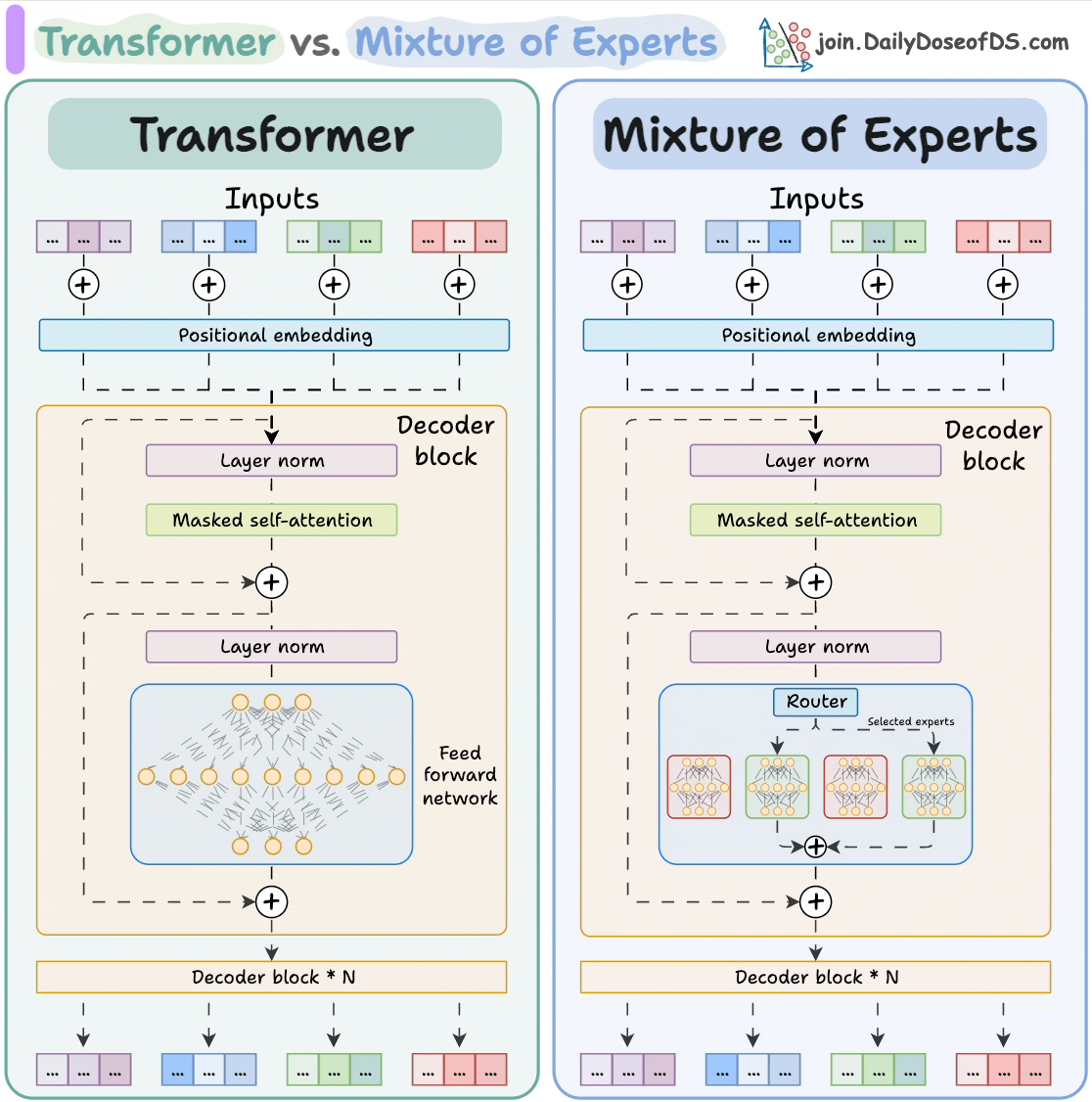
Load Balancing
The naive routing problem: the router might always prefer a few popular experts and ignore the rest, wasting capacity. To prevent this, MoE training adds an auxiliary load-balancing loss that encourages each expert to receive roughly equal token traffic. Without it, expert collapse is common.
MoE in Production
MoE is now standard in the largest production language models. Mixtral 8x7B routes each token through 2 of 8 experts, giving it the inference cost of a ~13B dense model with the capacity of a much larger one. GPT-4 is widely believed to be MoE. The architecture is also spreading to multimodal models, where different modalities can be routed to specialized experts.
MoE Trade-offs
MoE models are harder to serve than dense models. All experts must be loaded into memory (or distributed across devices) even though only a few fire per token. A Mixtral 8x7B requires ~90GB of VRAM to serve in full precision — more than a dense 70B model in 4-bit. The compute savings are real, but the memory footprint is a practical constraint you'll hit in deployment.
A MoE transformer has 8 experts per layer and routes each token to the top-2. Compared to a dense transformer with the same per-token FLOPs, what does the MoE model gain?