Retrieval-Augmented Generation (RAG)
The pattern: instead of relying on the LLM's training data alone, retrieve relevant documents from a vector database at query time and include them in the prompt. The LLM then generates an answer grounded in the retrieved content.
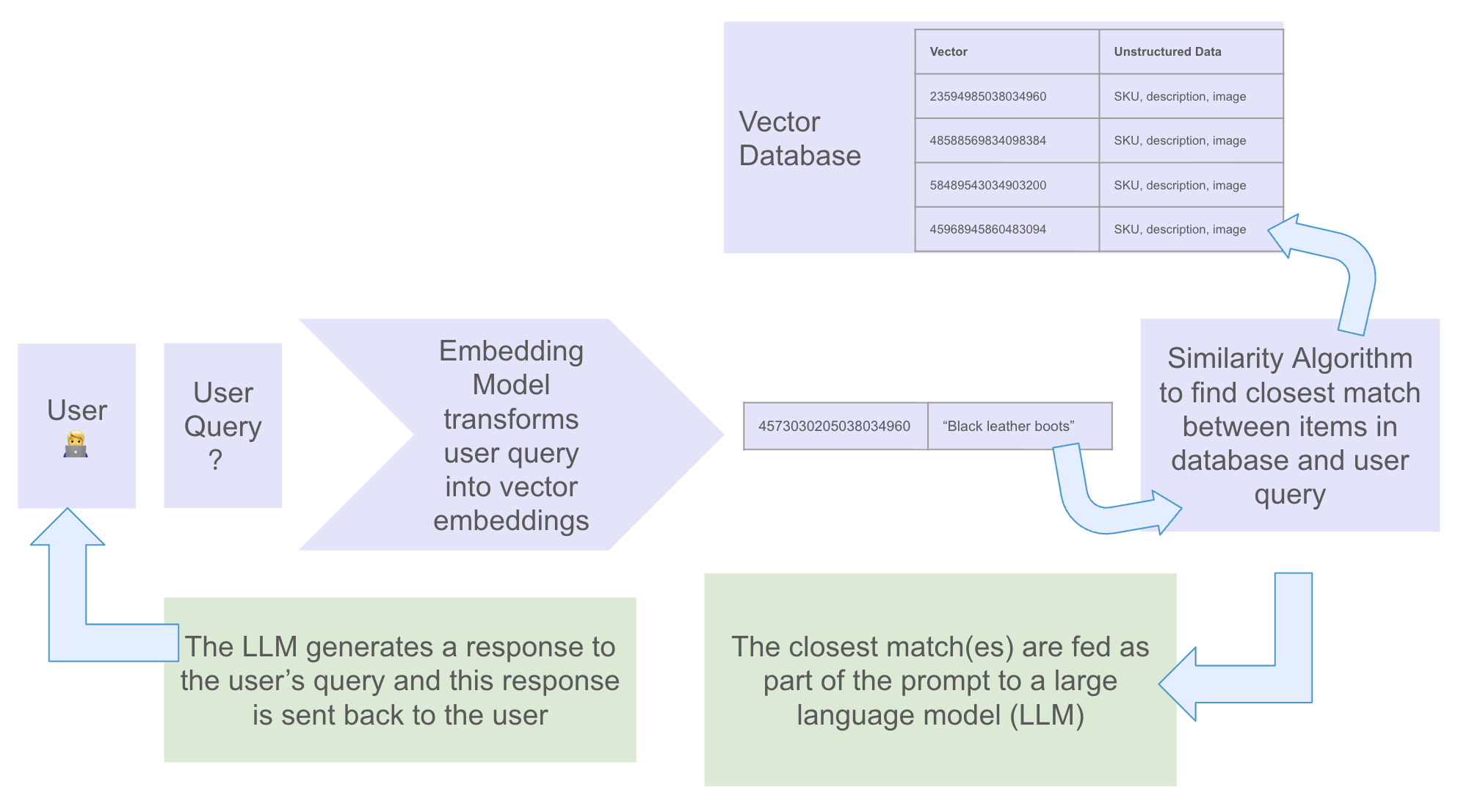
End-to-end pipeline:
- User query comes in.
- Embedding model converts the query into a vector.
- Similarity algorithm searches the vector database for the closest matches.
- Closest matches are inserted into the prompt.
- LLM generates a response grounded in the retrieved context.
- Response returned to the user.

RAG Is Not the Easy NLP Project
There's a story going around that RAG is the "easy NLP project." It is not. It is a large can of worms. Here are the design decisions you have to make — and every single one of them interacts with every other one.
Design Decision 1: Chunking
You can't put a whole 200-page PDF in the vector database as one chunk. You have to split. By sentence? Paragraph? Section? Document? Each choice has different retrieval behavior.
- Sentence-level gives precise retrieval but loses context.
- Paragraph-level is a common middle ground.
- Section-level works well for structured documents.
- Custom manual chunking sometimes outperforms everything else but is labor-intensive.
Design Decision 2: Embedding Model
Which embedding model do you use? Consider: accuracy for your application, open source vs. paid license, hosting difficulty, and ease of integration. The Hugging Face MTEB leaderboard is a good starting point.
Design Decision 3: Similarity Method
Cosine? Euclidean? Dot product? BM25 hybrid? The answer depends on your data and your model. Test.
Design Decision 4: The LLM
Which LLM generates the final answer? Accuracy for your application, cost (per-token pricing varies by orders of magnitude), deployment requirements, and whether you've evaluated the rest of the pipeline against your target LLM specifically.
Design Decision 5: Evaluation
Before you build, answer two questions: How will you evaluate it? and What will you need to evaluate it? The answer shapes everything — you may need to build a labeled dataset before you write a single line of pipeline code.
Your options, each with its own tradeoffs:
- User judgment — A/B testing, user research metrics, thumbs up/down. Ground truth from real users. Slow to collect, requires traffic, and users won't tell you why something failed.
- LLM-as-a-judge — Ask a model to score outputs. Fast and scalable. Works better with a different model as judge, or multiple judges, to reduce self-serving bias. Still requires a rubric and is only as good as your prompt.
- Text similarity metrics — Compare outputs to desired outputs in embedding space (or via BLEU/ROUGE). Requires a dataset of desired outputs — either an existing benchmark or one you build yourself. Cheap to run; the bottleneck is building the dataset.
- Basic metrics — Latency and inference cost. Easy to measure, but tell you nothing about answer quality. Necessary but not sufficient.
None of these is a silver bullet. Production systems typically combine at least two: fast automated metrics for regression testing, plus periodic human or LLM-as-a-judge review for quality.
This pipeline runs once — or whenever your source documents change.
Unstructured Data
Raw documents: PDFs, web pages, markdown files, database exports, images with captions — anything you want the LLM to be able to reference.
The quality and coverage of your source data is the ceiling on RAG performance. Garbage in, garbage out. You need enough representative data to cover the query space you expect.
Current configuration
⚠ Hybrid search requires both a vector store and a BM25 index. More infra complexity, but usually worth it.
Configure a RAG pipeline step by step. See how each design decision affects the others and explore tradeoffs for different application types.