The Curse of Evaluation
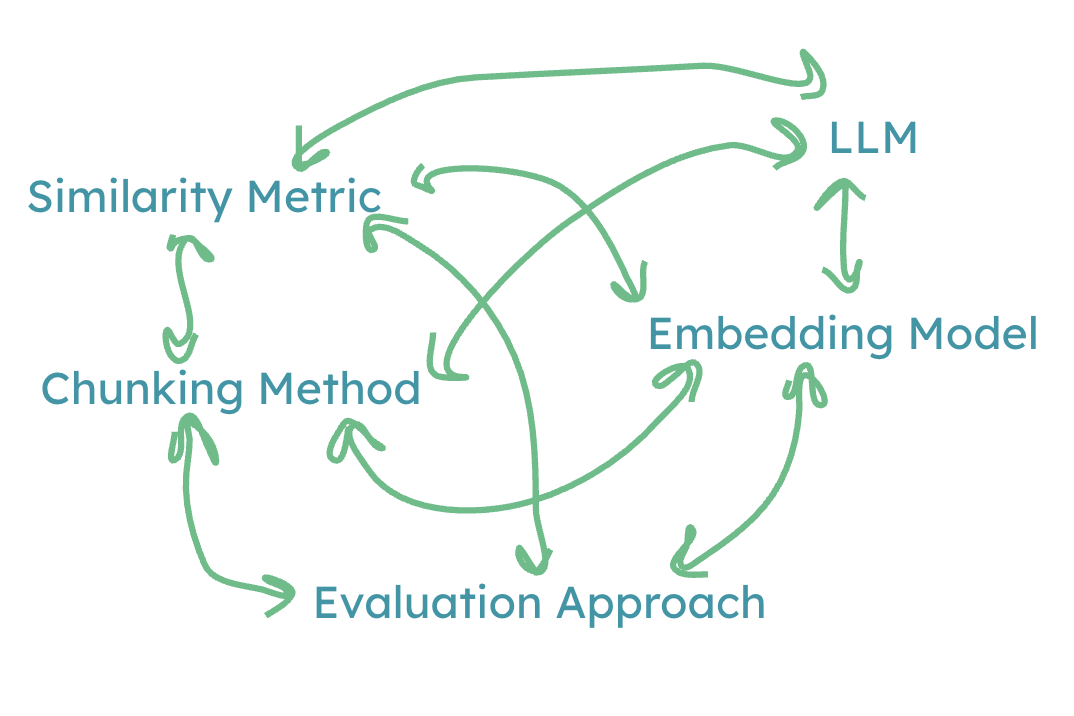
You have five major design dimensions: chunking method, embedding model, similarity metric, LLM, and evaluation approach itself.
Best practice for evaluation is to hold everything constant and vary one dimension at a time:
- Hold embedding model, similarity metric, LLM constant. Vary chunking. Pick the best.
- Hold chunking, similarity metric, LLM constant. Vary embedding model. Pick the best.
- Hold chunking, embedding model, LLM constant. Vary similarity metric. Pick the best.
- Hold chunking, embedding model, similarity metric constant. Vary LLM. Pick the best.
The problem: changing one decision invalidates the others. When you swap the LLM, the optimal chunking might shift. Do you re-run the chunking evaluation? At what point do you have a publication-quality study and a deployment that's six months behind?
This is the Curse of Evaluation, and it's the dominant source of pain in industry RAG implementations. A huge fraction of consulting work in this space is just "help us figure out how to evaluate our system." There is no best practice yet. The field is figuring this out in real time.
Answer Evaluation Questions Before Writing Code
The most important questions in any LLM-based system: How will you evaluate it? What will you need to evaluate it? If you can't answer these before writing any code, you'll spend three months building something you can't tell is working. Answer evaluation questions first. Build second.
You are building a RAG system for a company's internal documentation. You've chosen paragraph-level chunking, a specific open-source embedding model, cosine similarity, and GPT-4 as your LLM. Describe how you would evaluate the system, including what you would measure and how you would build your evaluation dataset.