Vision Transformers
A Note Before We Begin
This chapter covers territory that connects to two other major topics in this course: transformers (covered in depth in the NLP Unit) and diffusion models (covered in the Generative AI Unit). We will give you a brief overview of how these architectures apply to computer vision, but recommend reviewing the other units for in-depth coverage.
Think of this chapter as a preview. By the time you finish the NLP and Generative AI Units, everything introduced here will click more fully into place.
The transformer architecture was originally designed to process sequences of tokens — words, subwords, characters. A team at Google Brain in 2021 asked a creative question: what if we treated image patches as tokens?
The Vision Transformer (ViT) works like this:
- Divide the input image into fixed-size patches (typically 16 × 16 pixels).
- Flatten each patch into a 1D vector.
- Project each flattened patch through a learned linear embedding.
- Add positional embeddings to encode each patch's location in the image.
- Feed the resulting sequence of patch embeddings through a standard transformer encoder (multi-head attention + MLP blocks + layer normalization + residual connections).
- Use the output for the downstream task (classification, detection, etc.).
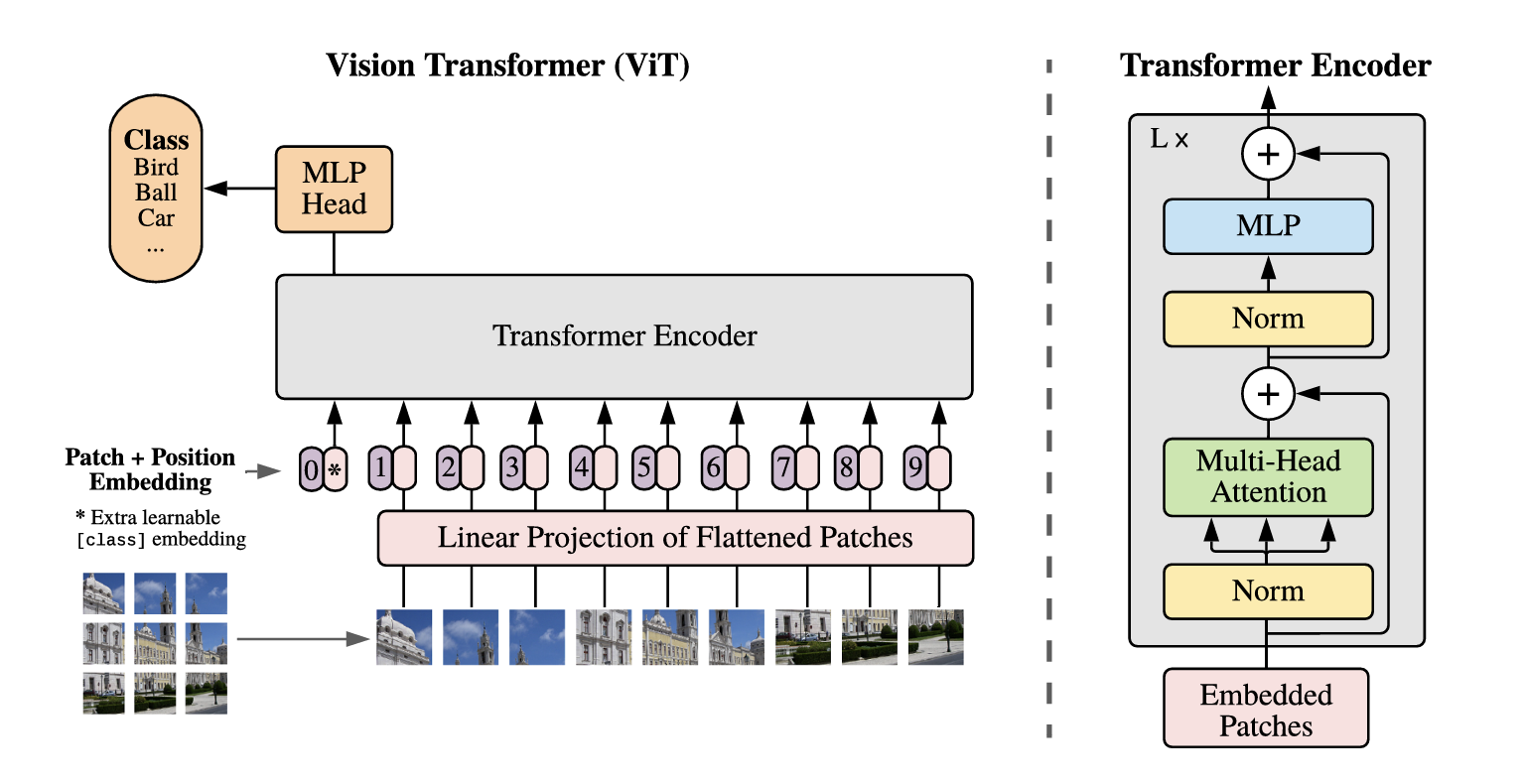
The key ingredient, multi-head attention, allows each patch to "attend to" every other patch in the image simultaneously. From the very first layer, a patch in the top-left corner can influence a patch in the bottom-right corner. CNNs, by contrast, build global context only gradually, through many stacked local operations.
This global receptive field gives ViT strong performance on large datasets and makes it naturally suited for tasks that require reasoning about long-range relationships between parts of an image. The tradeoff: ViT requires more data and more compute than CNNs, and may miss the fine-grained local features that CNN inductive biases naturally capture.
Real World: Multimodal Applications
The transformer's ability to process sequences makes it naturally suited for tasks that combine images and text — visual question answering, image captioning, medical report generation from scans. Vision transformers are the backbone of most state-of-the-art multimodal systems.
A key architectural difference between CNNs and Vision Transformers is how they build global context. Which statement correctly describes this difference?