Grounding DINO and SAM
Grounding DINO: Zero-Shot Object Detection
Zero-shot detection means the model can detect objects it was never explicitly trained to detect. You describe an object in natural language, and the model finds it in an image — even if that object was not in the training set.
Grounding DINO achieves this by fusing vision and language at multiple stages of the architecture. It uses a text backbone (the BERT transformer) to process text descriptions and an image backbone (the Swin transformer) to process images, then combines text and image features in a shared representation space. Because text and image features are mapped into the same space, the model can respond to arbitrary text descriptions at inference time.
This has set new records on zero-shot detection benchmarks, including the ODINW zero-shot benchmark.
Grounding DINO Architecture
Grounding DINO takes a text description and an image as inputs. It processes them through separate backbones, fuses the two modalities repeatedly via cross-attention, then decodes the fused features into bounding boxes aligned to the text prompt. Because text and image are mapped into the same feature space, the model can detect any object describable in language — including objects never seen during training.
Click each tab to step through the Grounding DINO architecture — from dual backbones through cross-attention fusion to text-aligned bounding box output.
Segment Anything Model (SAM)
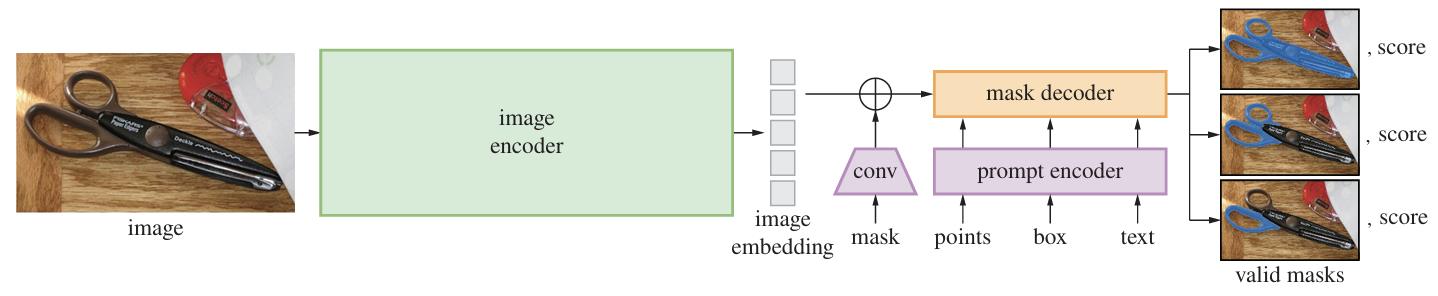
Meta's Segment Anything Model (2023) is designed to be a general-purpose segmentation engine. Its architecture consists of three components:
- Image Encoder — A Vision Transformer that computes image embeddings once per image.
- Prompt Encoder — Handles prompts in various forms: points, boxes, text, or masks that indicate what to segment.
- Mask Decoder — A transformer-based decoder that combines image embeddings with prompt embeddings through cross-attention, producing a segmentation mask.
The critical design choice: the image encoder runs once, and the prompt encoder + mask decoder are lightweight enough to run interactively. You can click on an object, drag a box, or type a description, and receive a precise segmentation mask in real time.
Grounding SAM (2024) combines Grounding DINO for text-prompted detection with SAM for segmentation: describe what you want to segment in natural language, and the system both detects and segments it — without any task-specific training.