Diffusion Models
Diffusion models underpin most state-of-the-art image generation systems — Stable Diffusion, DALL·E 2 and 3, Flux, and others. We will cover them in detail in the Generative AI module. For now, the essential idea:
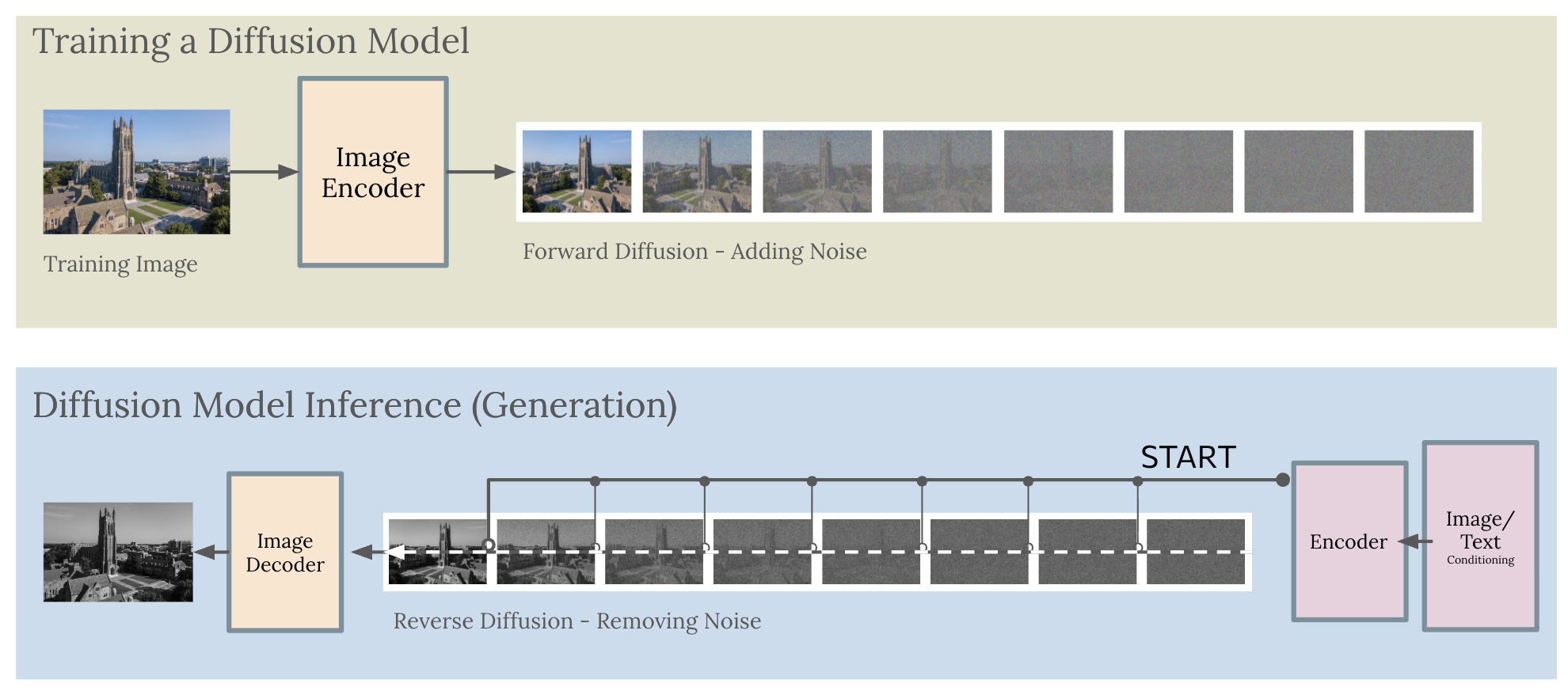
Training a diffusion model involves two phases:
- Forward process — Gradually add Gaussian noise to training images over many steps, until the image is pure noise. At each step, record how much noise was added. This is your dataset!
- Reverse process — Train a neural network to predict and remove the noise at each step, working backwards from pure noise to a clean image.
Once trained, the model can generate new images by starting with random noise and running the reverse process. The quality of the output depends on the accuracy of the noise prediction at each step.
Text-conditional generation adds a guidance mechanism: the noise predictor is conditioned on a text embedding, steering the reverse diffusion process toward images that match the text description. The implementation consists of the U-Net architecture combined with cross-attention to incorporate text embeddings.
Real World: Synthetic Training Data
Diffusion models are increasingly used to generate synthetic training data for computer vision models. You can generate thousands of diverse images of rare defects for a manufacturing inspection system, or diverse lighting conditions for a surveillance model. This closes the loop with the synthetic data strategy introduced in Chapter 1: what once required purpose-built rendering pipelines can now be prompted in natural language.
Grounding SAM can segment any object described in natural language without task-specific training. Given this capability, in what kinds of computer vision problems would you still prefer a fine-tuned, task-specific model?