Queries, Keys, Values, and Multi-Head Attention
Making Attention Trainable: Q, K, V
So far, nothing is being learned. We've just done arithmetic. To let the network learn how to attend, we introduce three trainable matrices:
- The Query matrix
M_Q - The Key matrix
M_K - The Value matrix
M_V
Each original embedding v_i gets transformed three times: q_i = v_i · M_Q, k_i = v_i · M_K, val_i = v_i · M_V. Now scores are computed as q_i · k_j, and the output is a weighted sum of values (not original embeddings). By training Q, K, and V, the network learns what kinds of comparisons to make and what information to retrieve.
The names are borrowed from database semantics — you have a query, you match it against keys, you retrieve values. The metaphor is rather imperfect, so don't think too deeply about it.
The full pipeline for one token
Dot product → Normalize → Weighted sum
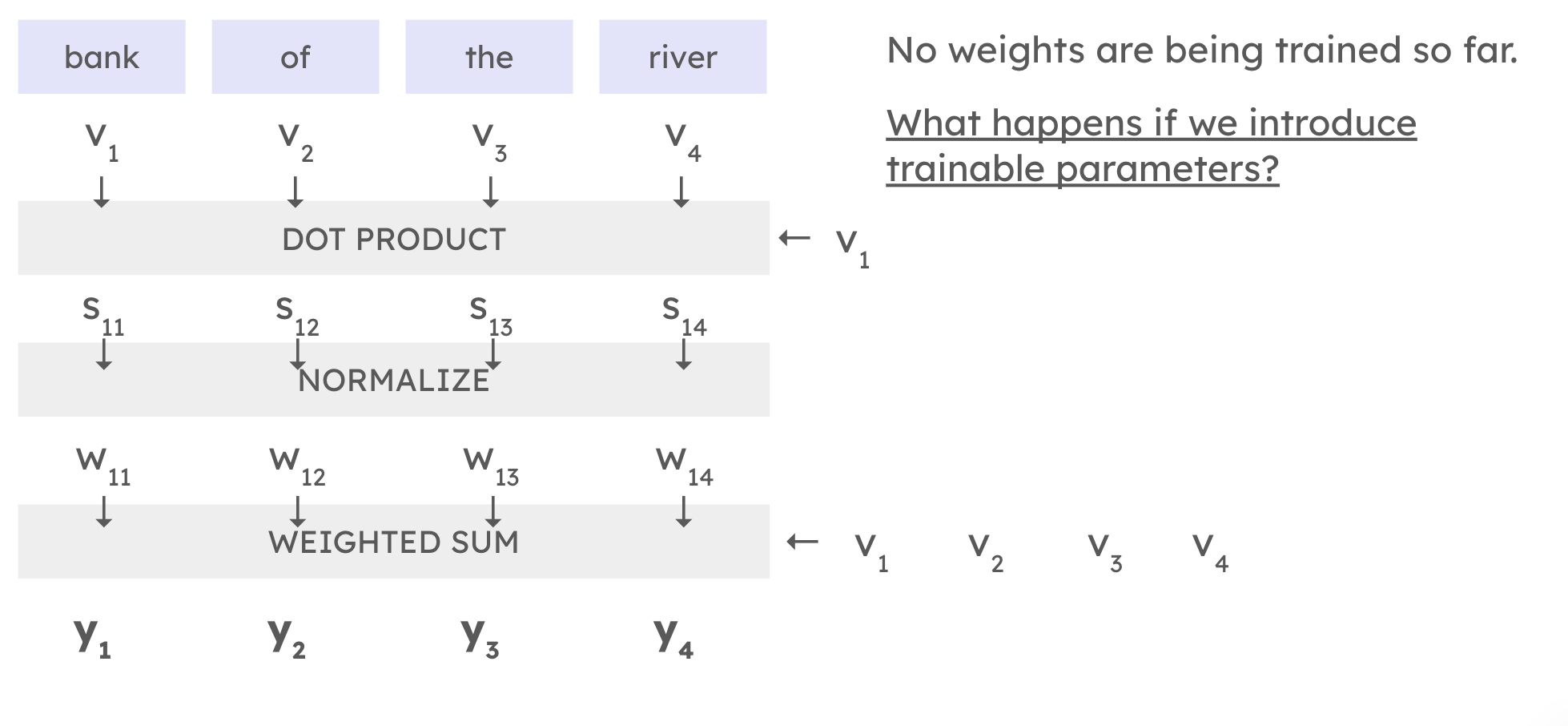
This view shows the complete three-stage pipeline for building y₁. The input embeddings v₁–v₄ flow into a dot product with v₁ to produce scores s₁₁–s₁₄. Those scores flow into normalize (softmax) to produce weights w₁₁–w₁₄. Finally, the weights and the original embeddings v₁–v₄ flow into a weighted sum to produce y₁–y₄. Notice that the same raw embeddings appear twice: once as the things being scored against, and again as the things being blended.
Step through how trainable Query, Key, and Value matrices are introduced into the self-attention pipeline.
Multi-Head Attention
The problem: one relationship at a time
A single attention head can only capture one type of context

Consider the sentence "I gave my cat Tater a toy." Focus on the word "gave" (highlighted in orange). To fully understand it, the model needs to track at least three distinct relationships simultaneously: who gave (→ "I"), to whom (→ "Tater"), and what (→ "toy"). A single self-attention head computes one weighted blend of the sequence — it can lean toward one of these relationships, but not all three at once. The solution is to run multiple attention mechanisms in parallel, each free to specialise on a different relationship.
Step through how multiple attention heads run in parallel to capture different relationships, then get combined into a single output.
Self-Attention vs. Cross-Attention
Self-attention operates within a single sequence — every token attends to every other token in the same input.
Cross-attention operates between two different sequences. For each element in one sequence (the query sequence), cross-attention computes attention scores based on its relationship with every element in a separate sequence (the key-value sequence). This lets the model selectively focus on the most relevant parts of the other sequence when generating each output.
Machine translation is the classic example: the decoder generates the target language word by word, and at each step it uses cross-attention to decide which parts of the encoded source sentence to draw from.