Latent Stable Diffusion Architecture
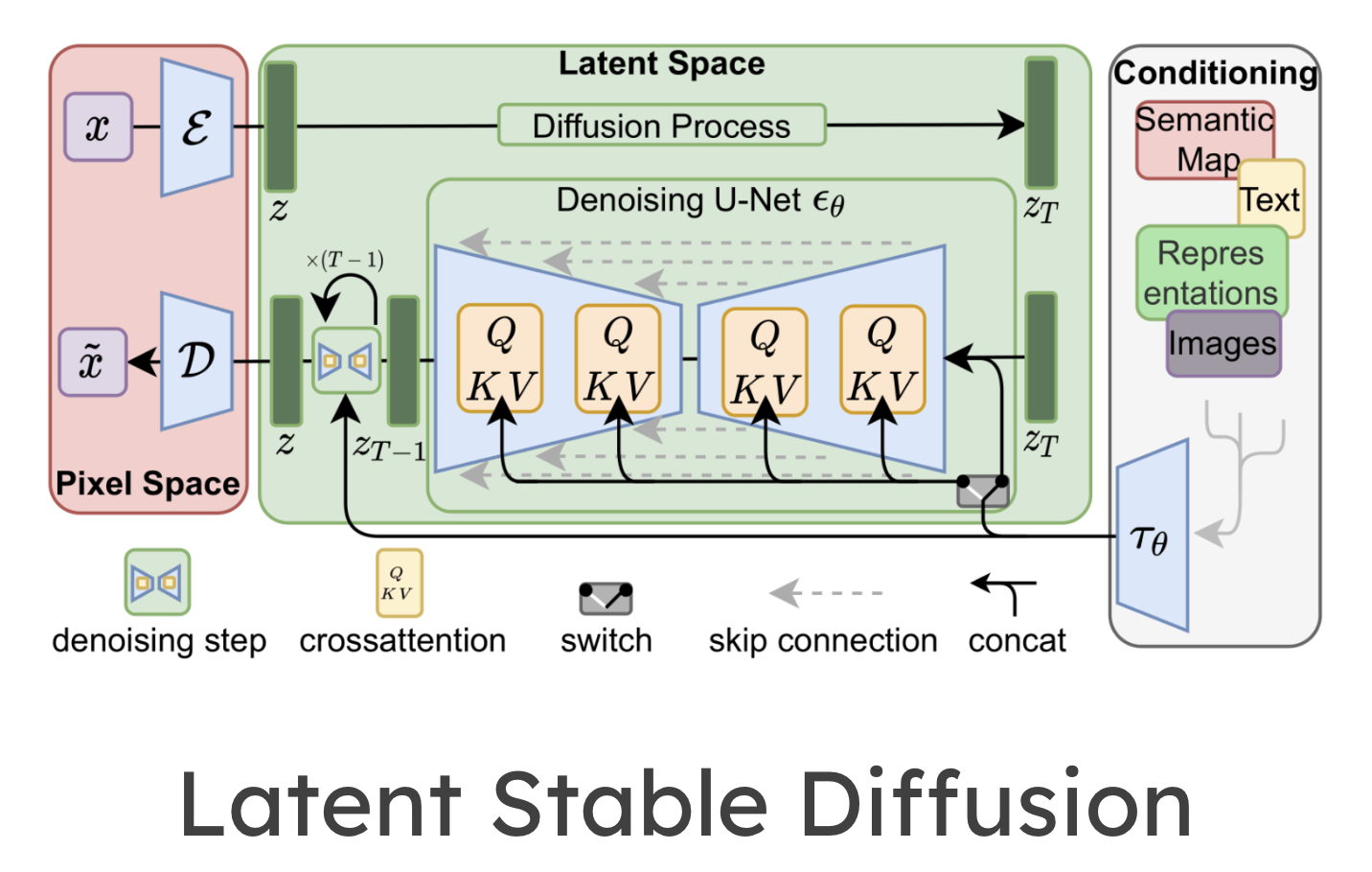
Here's where things get exciting: every architecture we've covered in this course shows up inside a modern diffusion model. The Latent Stable Diffusion architecture (Rombach et al., 2022) integrates autoencoders, U-Nets, transformer text encoders, and cross-attention into a single system. Let's walk through each component.
Every idea in this course, integrated!
A single modern image generation system uses:
- Autoencoders (Recommendation Systems chapter) to compress images to a workable latent space
- U-Nets (Computer Vision chapter) as the noise predictor
- Transformers and attention (NLP chapters) as the text encoder
- Cross-attention (NLP chapters) to bridge text and image
You already know all the pieces. We're assembling them in a new way.
Select a component above
Each component in this architecture comes from a chapter you've already studied. Click to see its role and how it connects to the next stage.
Walk through the Latent Stable Diffusion architecture component by component. Click each building block to see which earlier chapter introduced it, what it does here, and how it connects to the next component.
Classifier Guidance
To steer diffusion beyond text conditioning, we can use a pretrained classifier. If we have a classifier trained to recognize ImageNet classes, we can use the gradient of that classifier to nudge the denoising process at each step toward a specified class. Want "golden retriever"? Use a classifier, take its gradient, and steer the reverse diffusion. This is classifier guidance.
Classifier-free guidance (CFG) is the modern version: train the model to condition on text, but also occasionally train it with no conditioning (randomly masking the text). At inference time, you run the model twice — once conditioned, once unconditioned — and amplify the direction that differs between them. No separate classifier required, and you can tune a "guidance scale" to control how strongly the prompt influences the output.
Fine-Tuning Diffusion Models
You can fine-tune diffusion models on your own data. There's a 2025 paper titled Fine-Tuning Image-Conditional Diffusion Models is Easier Than You Think, and Hugging Face provides an excellent tutorial Colab notebook. Fine-tuning one yourself is genuinely the fastest way to internalize the architecture — you'll understand things from hands-on work that no lecture can convey.
Real-world applications of diffusion models
Diffusion models are essentially the entire current state of the art in generative imagery:
- Consumer image generation: DALL-E 2/3, Stable Diffusion, Midjourney, ChatGPT's image creator, Google's Imagen.
- Image editing and inpainting: Removing objects from photos, "generative fill" in Photoshop, expanding the canvas.
- Video generation: Sora and similar systems extend diffusion to the temporal dimension.
- Medical imaging: Reconstructing MRI scans from incomplete data, synthesizing training data for rare conditions.
- Drug discovery and protein design: RFdiffusion applies diffusion to protein structure generation.
- Audio generation: Music and speech synthesis models like AudioLDM use latent diffusion for audio.
When you see a "create an image" feature in any product today, it is almost certainly a diffusion model underneath.
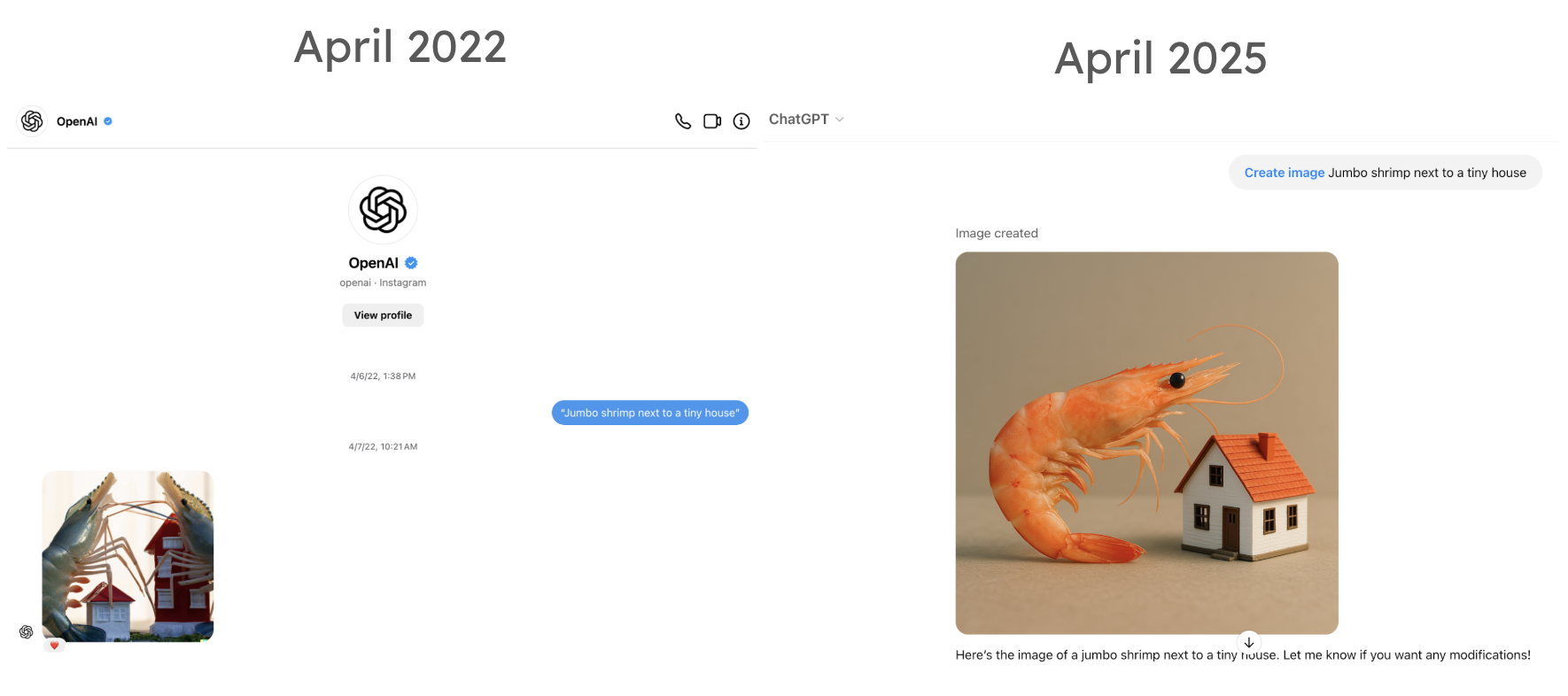
The same 'jumbo shrimp next to a tiny house' prompt produced a bizarre crustacean-dollhouse hybrid in DALL-E 2 (2022) and a photorealistic result in ChatGPT's image generation (2025). Beyond 'more compute,' what architectural and training improvements do you think account for the difference?
Latent Stable Diffusion operates in a compressed latent space rather than raw pixel space. What is the primary motivation for this design choice?