The Diffusion Intuition
The Physical Intuition
Think back to middle school chemistry. Diffusion describes the spreading of particles from a dense space to a less dense space. Drop blue food coloring into a glass of clear water and watch it spread until the whole glass is faintly blue. That gradual, spreading is diffusion.
Now imagine running that backward. If you watched a video of food coloring diffusing and played it in reverse, you'd see the diffuse blue water pull itself back together into a concentrated droplet. That's not physically possible in the real world — but it is mathematically possible if you've trained a model to predict, at every step, how the noise should be removed to reverse the process.
That's the entire core insight of diffusion models: take an image, gradually destroy it with noise, then train a model to undo the destruction one step at a time.
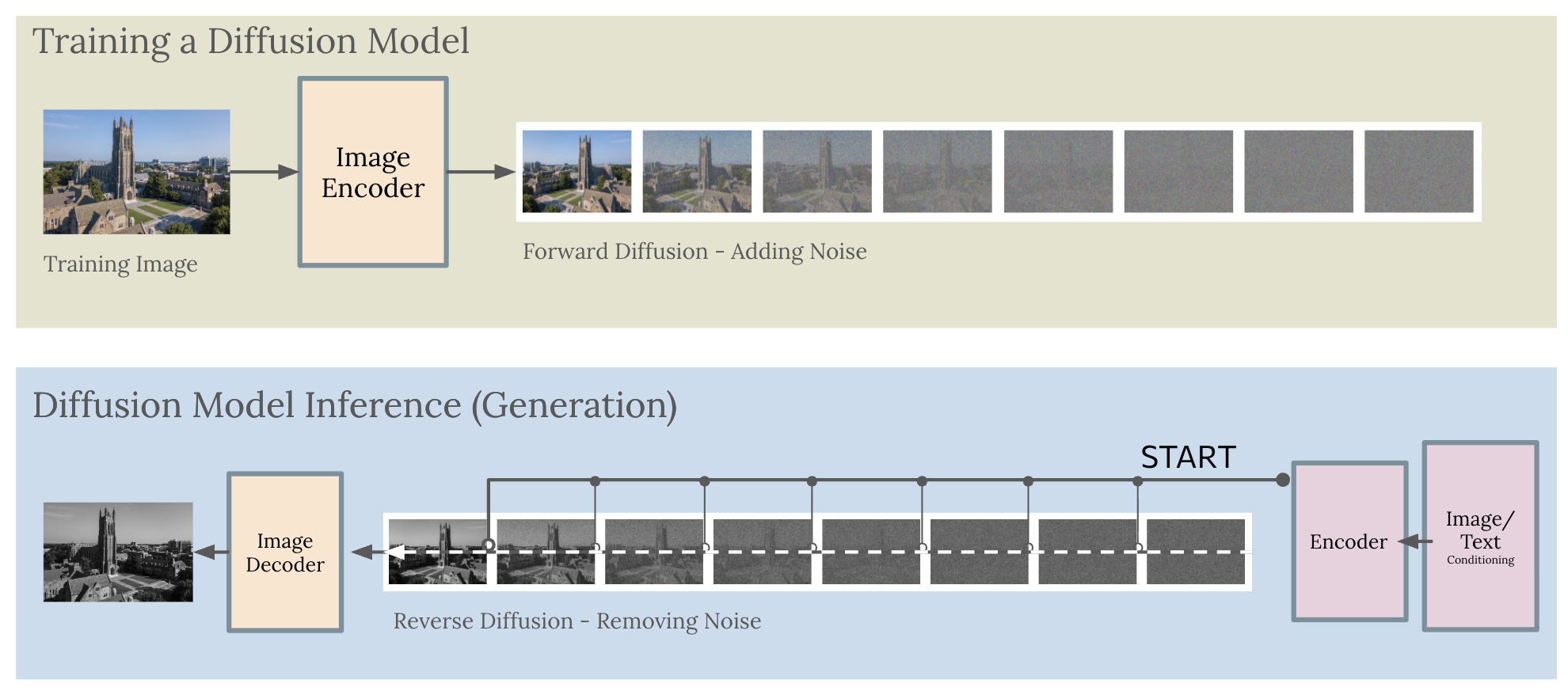
The Forward Process: Noising
This is the easy half. We take a training image and gradually add Gaussian noise over many timesteps T. The schedule by which we add noise (how much at each step) is fixed in advance. By time T, the image is pure Gaussian noise. Along the way we've created a sequence of progressively noisier images that serve as training targets for the reverse process. This is essentially creating our training dataset!
The Reverse Process: Denoising
At each step, we ask the model: "How much noise is in this image right now? Remove it." The model gradually denoises the image over T timesteps until we end up with a clean output.
Rather than training the model to remove all the noise at once, we train it to remove one step's worth of noise. This makes the problem much more tractable — each denoising step is a small, learnable correction rather than a miraculous reconstruction from noise.
Forward process — adding noise over 10 steps
Animated denoising
Gaussian noise is added incrementally at each step.
The key idea
The neural network doesn't learn to remove all the noise at once — it learns to remove one step's worth. At inference time, starting from pure random noise and applying this small denoising step T times produces a clean image. More timesteps = finer-grained denoising = better quality (but slower).
Watch the forward diffusion process in real time: a clean image is gradually corrupted to noise. Then run the reverse process to watch the model denoise it step by step. Adjust T to see how the number of timesteps affects quality.
In a diffusion model, what does the neural network actually learn to predict at each timestep?