YOLO and Faster R-CNN
YOLO: You Only Look Once
YOLO was a huge moment in real-time object detection. Rather than proposing and evaluating regions sequentially, YOLO reframes detection as a single regression problem over a spatial grid.
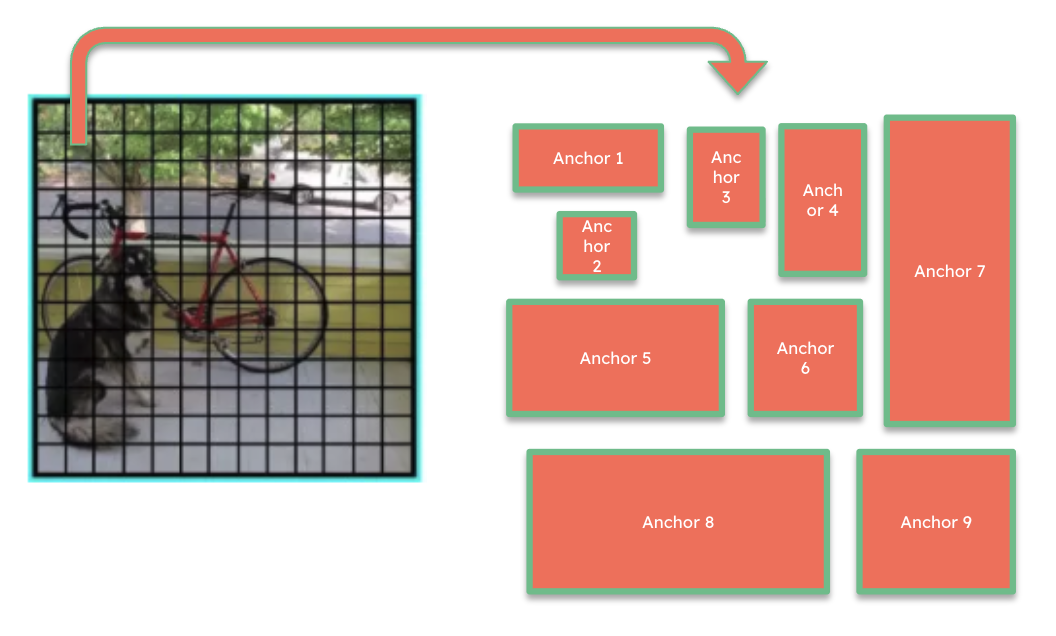
The image is divided into an S × S grid. Each cell is responsible for predicting objects whose center falls within that cell. Each cell predicts N bounding boxes (in YOLOv3, 9 anchor boxes per cell), producing S × S × N predictions per image — all computed in a single forward pass.
YOLOv3 predicts offsets from predefined anchor boxes rather than absolute coordinates. The backbone is DarkNet-53, essentially a ResNet architecture. The defining feature of YOLO is speed: it can run near real-time even on modest hardware.
The YOLO Family Today: YOLOv9, YOLO World, and Beyond
YOLO has continued to evolve well past v3. A few notable modern variants:
- YOLOv9 (2024) — Introduces Programmable Gradient Information (PGI) and a new backbone (GELAN) to address information loss in deep networks. Sets new speed/accuracy tradeoffs on COCO, outperforming earlier YOLO versions at comparable model sizes.
- YOLO World (2024) — Adds open-vocabulary detection by fusing text embeddings into the detection head. Rather than detecting a fixed class list, you describe what you want to find in natural language — e.g., "red traffic cone" or "cracked pavement" — without retraining the model.
- YOLO26 (2026) — The latest generation, designed for efficient deployment across scales from mobile to server. Continues the trend of NMS-free inference while improving accuracy on dense and small-object detection benchmarks.
The core trade-off remains the same across all variants: YOLO sacrifices some accuracy for dramatically lower latency. What has changed is how favorable that trade-off has become — modern YOLO variants are competitive with two-stage detectors on standard benchmarks while still running in real time.
Faster R-CNN
While YOLO optimizes for speed through a unified single-pass design, the R-CNN family optimizes for accuracy through a region-proposal pipeline.
The original R-CNN generated about 2,000 region proposals using selective search (a classical algorithm), ran each through a CNN separately, and classified it with an SVM. The result: 47 seconds per image. This was not very practical. Two specific bottlenecks drove this cost:
- CNN features had to be computed for each region proposal independently — roughly 2,000 forward passes per image — making both training and inference extremely slow.
- To train the SVMs, CNN features for every region proposal across all training images had to be cached to disk, requiring significant storage.
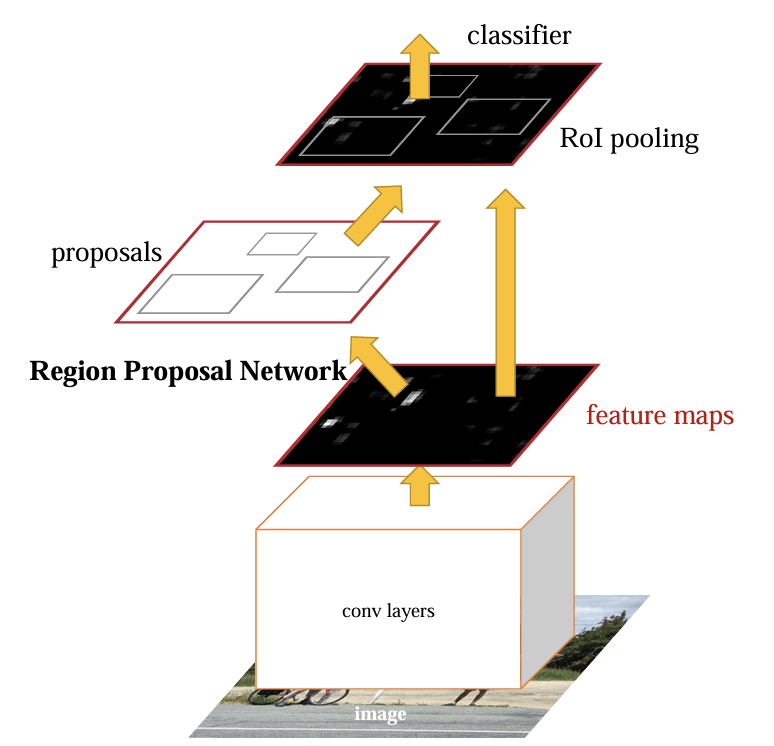
Faster R-CNN replaced the slow selective search with a neural network, the Region Proposal Network (RPN), that proposes regions as part of the model's forward pass. Instead of computing CNN features for each proposal separately, it computes features for the entire image once and extracts proposal features from the shared feature map using ROI Pooling. The entire pipeline is trained end-to-end with a single loss function.
The speed improvement: 0.2 seconds per image, compared to 47 seconds for the original R-CNN. Same fundamental idea, dramatically more efficient implementation.
Drag the RoI to move · drag its corner to resize · hover a bin or output cell to trace the computation
RoI Pooling: drag the yellow region of interest across the feature map and resize it — the output is always a fixed 3×3 grid regardless of RoI size. Hover a bin to highlight the corresponding feature-map region.
YOLO vs. Faster R-CNN: When to Use Each
- YOLO — When speed is critical: real-time video, edge devices, interactive applications. Trades some accuracy for dramatically lower latency.
- Faster R-CNN — When accuracy is critical: medical imaging analysis, offline batch processing, tasks where false negatives are costly. Trades speed for more precise localization.
You are building a system to count and classify fish species from underwater video footage — footage that is captured and analyzed overnight, not in real time. There are 40 fish species, some of which look very similar and appear in small sizes in the frame. Which detection architecture would you favor and why?