VGGNet, Accuracy Saturation, and the ResNet Breakthrough
VGGNet: Going Bigger (2014)
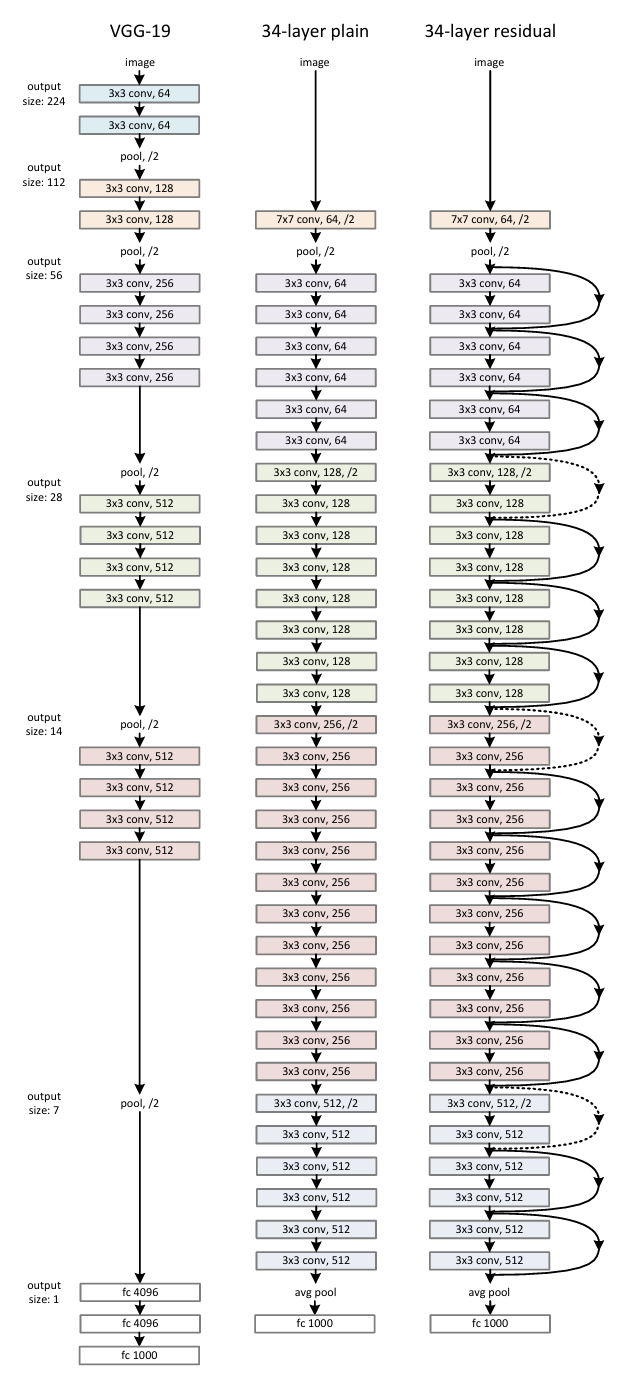
Following AlexNet's success, researchers began exploring what made deep CNNs work. VGGNet (developed by the Visual Geometry Group at Oxford) made a bold bet on simplicity: use only 3 × 3 convolutional filters, everywhere, and make the network deeper.
The intuition was sound. Multiple stacked 3 × 3 filters have the same receptive field as a larger filter but learn more complex features with fewer parameters. VGGNet architectures ranged from 11 to 19 weight layers — VGG11, VGG13, VGG16, VGG19 — and they performed well.
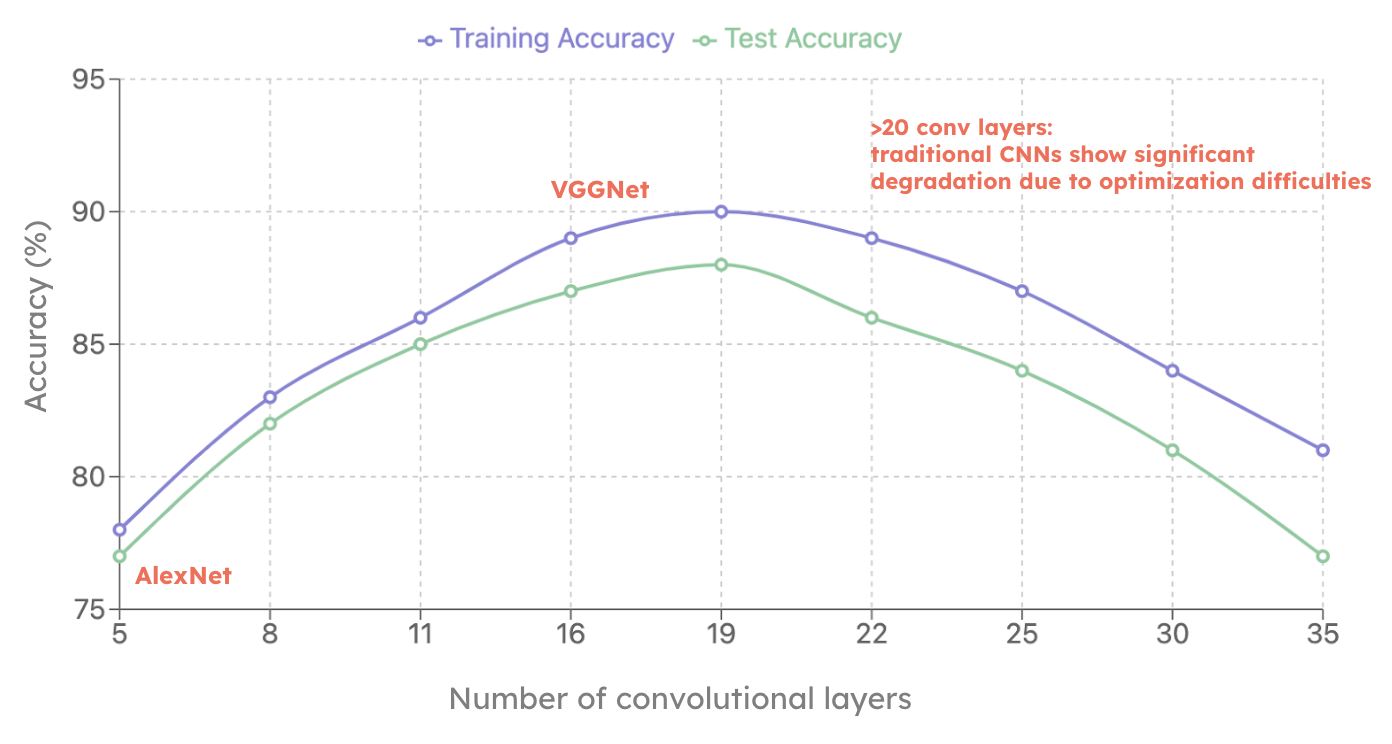
But VGGNet revealed something troubling: at some point, adding more layers stopped helping. Beyond about 20 convolutional layers, accuracy began to degrade — on both training and test sets simultaneously. The community called this accuracy saturation.
The Depth Problem and Why It Exists
Here is the puzzle accuracy saturation poses: theoretically, a deeper network should be at least as good as a shallower one. The extra layers could simply learn to pass their input through unchanged — the identity function. That would make the deeper network behaviorally equivalent to the shallow one.
But in practice, teaching a stack of nonlinear layers to collectively behave as an identity function is surprisingly hard for gradient-based optimization. Each layer applies a nonlinear transformation. Getting all of those transformations to precisely cancel each other out is like balancing a series of complex equations to get back to your starting point. The optimization landscape becomes increasingly complicated with depth.
ResNet: Residual Connections Solve the Problem (2015)
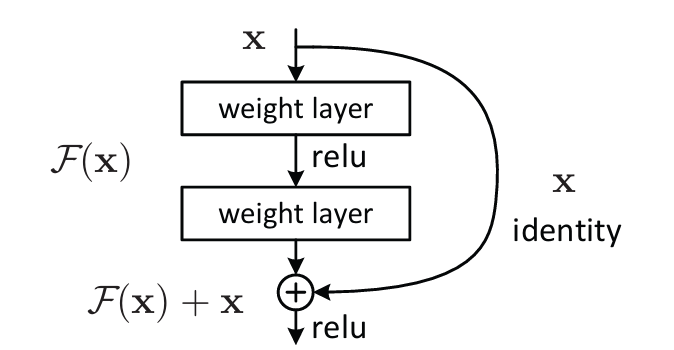
The breakthrough was skip connections (also called residual connections). Rather than forcing every layer to learn a full transformation, skip connections route the input around a layer and add it directly to that layer's output:
output = F(x) + x
This means a layer can replicate the identity function simply by setting its weights to zero — the skip connection carries the input through unchanged. The network is effectively preconditioned with identity mappings as a starting point, so each layer only needs to learn the residual: the difference from identity, rather than the full transformation from scratch.
Why is this better?
1. Better gradient flow. In very deep networks, gradients shrink as they travel backward through many layers — the vanishing gradient problem. Skip connections act as a highway, letting gradients flow directly to earlier layers without passing through every transformation. Even layers deep in the network receive strong gradient signals during training.
2. Adaptive layers. Rather than forcing every layer to contribute, the network can learn which transformations are actually needed. Early in training, some layers may be effectively skipped. As training progresses, those layers gradually activate to capture more complex features — only when the residual is worth learning.
The practical effect was dramatic. ResNets with 34, 50, 101, and even 152 layers outperformed shallower networks. Bigger was finally better again.
Real World: Production Inference
ResNet50 (a 50-layer residual network) is one of the most widely deployed computer vision backbones in industry. It hits a practical sweet spot between accuracy and inference speed. Variants like ResNet18 are used on edge devices where compute is constrained.
Why does accuracy degrade when you add more layers to a standard CNN (VGGNet-style), even on the training set?