Autoencoders and the Generation Problem
We met autoencoders in the Recommendation Systems chapter, but here's the refresher. An autoencoder is two networks glued together:
- The encoder is a neural network that learns to compress data into a much smaller representation, a vector we call z.
- The decoder is another neural network that learns to reconstruct the original input from that compressed representation.
The whole thing is trained end-to-end to minimize reconstruction error: we want x' (the decoder's output) to be as close to x (the original input) as possible.
Width represents vector dimensionality — compression then expansion
Hover or click a layer
See how each layer transforms the data as it flows through the autoencoder.
The autoencoder architecture you met in the Recommendation Systems unit. The encoder compresses to a latent vector z; the decoder reconstructs from z. Here we visualize what the latent space looks like for a simple image dataset.
The Problem When We Try to Generate
The decoder of a trained autoencoder is essentially a function from a low-dimensional vector to a realistic-looking output. That sounds like a generator! Could we just train an autoencoder and then sample random vectors and feed them into the decoder?
We could try. It won't work very well. And here's why:
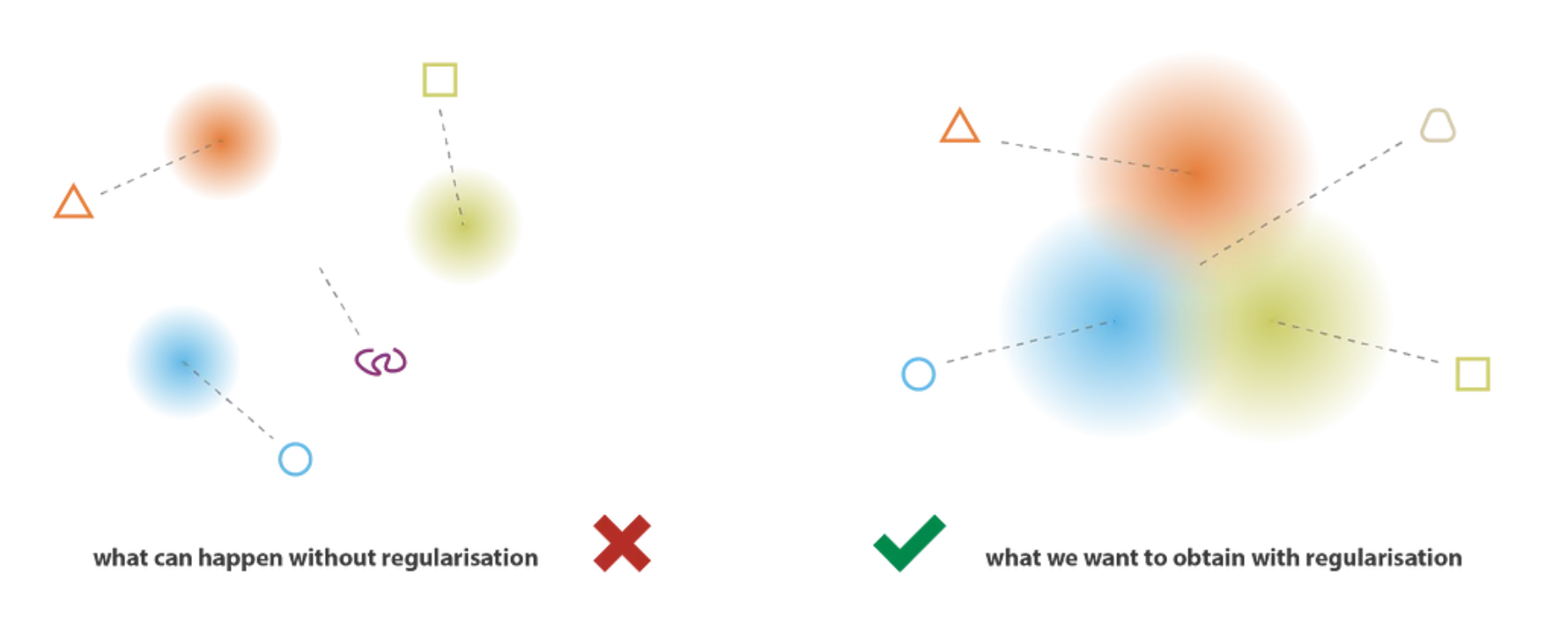
When we train an autoencoder to minimize reconstruction error, nothing in the loss function forces the latent space to be well-organized. The encoder might learn to scatter training examples to weird, isolated points in latent space — wherever happens to make reconstruction easiest. If you sample a random point from somewhere between those clusters, the decoder has never seen anything like it and produces gibberish.
We need the latent space to be regular for generation to work. Specifically:
- Continuity: Two close points in latent space should decode to similar outputs. No wild discontinuities.
- Completeness: Any point sampled from the latent space should decode to something meaningful. No "dead zones."
You train a vanilla autoencoder on images of faces and achieve excellent reconstruction error on the training set. When you sample a random point from the latent space and decode it, the output is unrecognizable noise. What is the most likely cause?