The GAN Framework
GANs are a clever use of game theory. You take two neural networks and pit them against each other:
- The Generator tries to create fake samples that look like the real training data.
- The Discriminator tries to tell the difference between real samples (from the training set) and fake samples (from the generator).
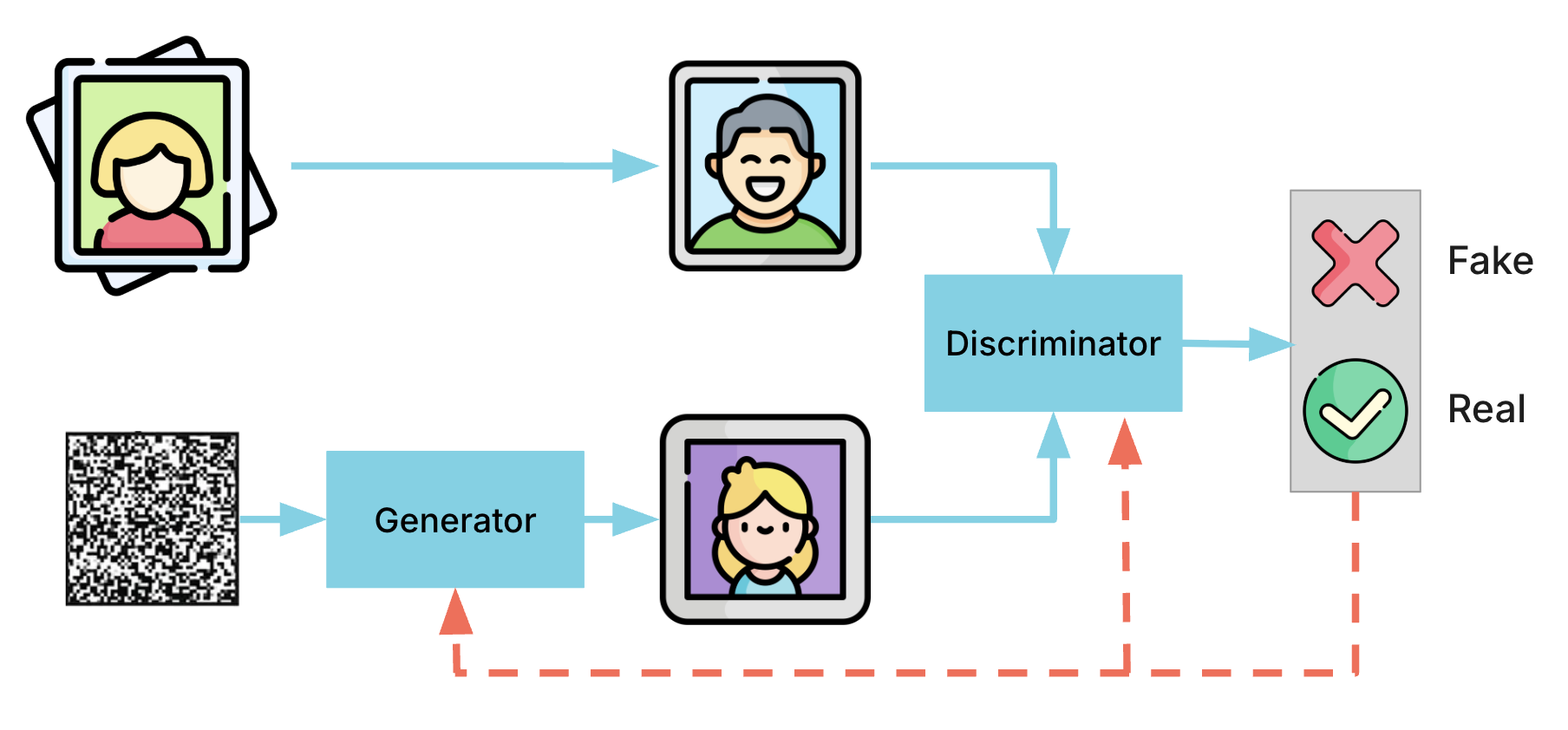
The Generator
The generator takes in random noise, a fixed-length vector sampled from a simple distribution like a Gaussian or uniform. This is a meaningless embedding. Pure randomness. The generator's job is to map this noise into an embedding that lives in the same space as your training data and then decode that embedding into something that looks like a real sample.
- The noise input is usually significantly lower-dimensional than the output.
- The architecture can be convolutional, fully connected, or any combination.
- The representations the model learns in latent space are latent representations, intended to capture the underlying distribution of the training data.
The Discriminator
The discriminator is much simpler. It's just a binary classifier: given an image, is this real or is this fake? We only use the discriminator for training. Once training is done, we discard it.
Click any step
Learn what each component does and why it exists.
Step through the GAN forward pass: trace how noise becomes a generated sample, how the discriminator scores it, and how gradients flow back to each network.
After GAN training is complete, which component do you keep and use for inference?