Adversarial Attacks
Challenge 5: Adversarial Attacks
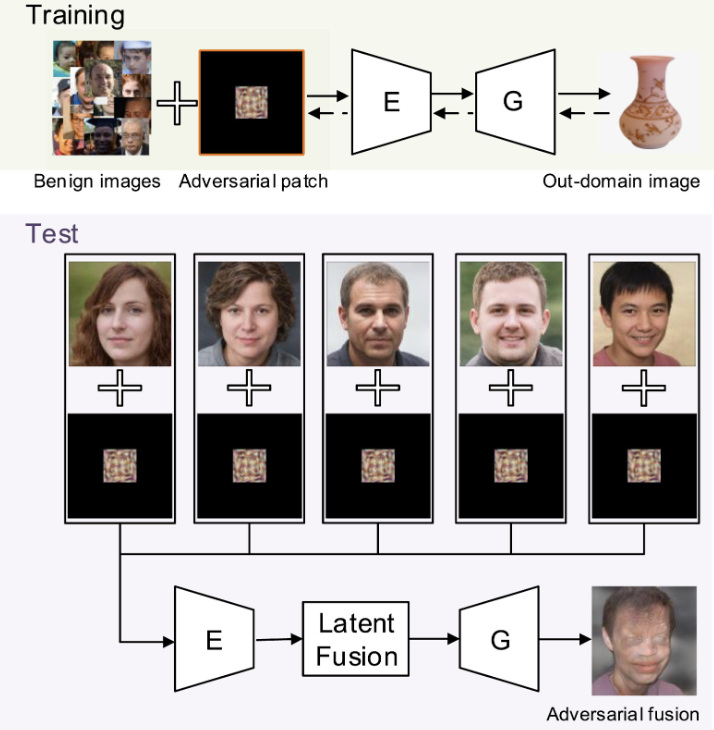
Generative models are particularly vulnerable to adversarial attacks — small, often imperceptible perturbations of the input that cause large changes in the output. A barely-visible patch on an input image can cause an image classifier to misclassify it spectacularly. For generative models that condition on inputs, the same dynamic applies, and the consequences can be much worse than misclassification.
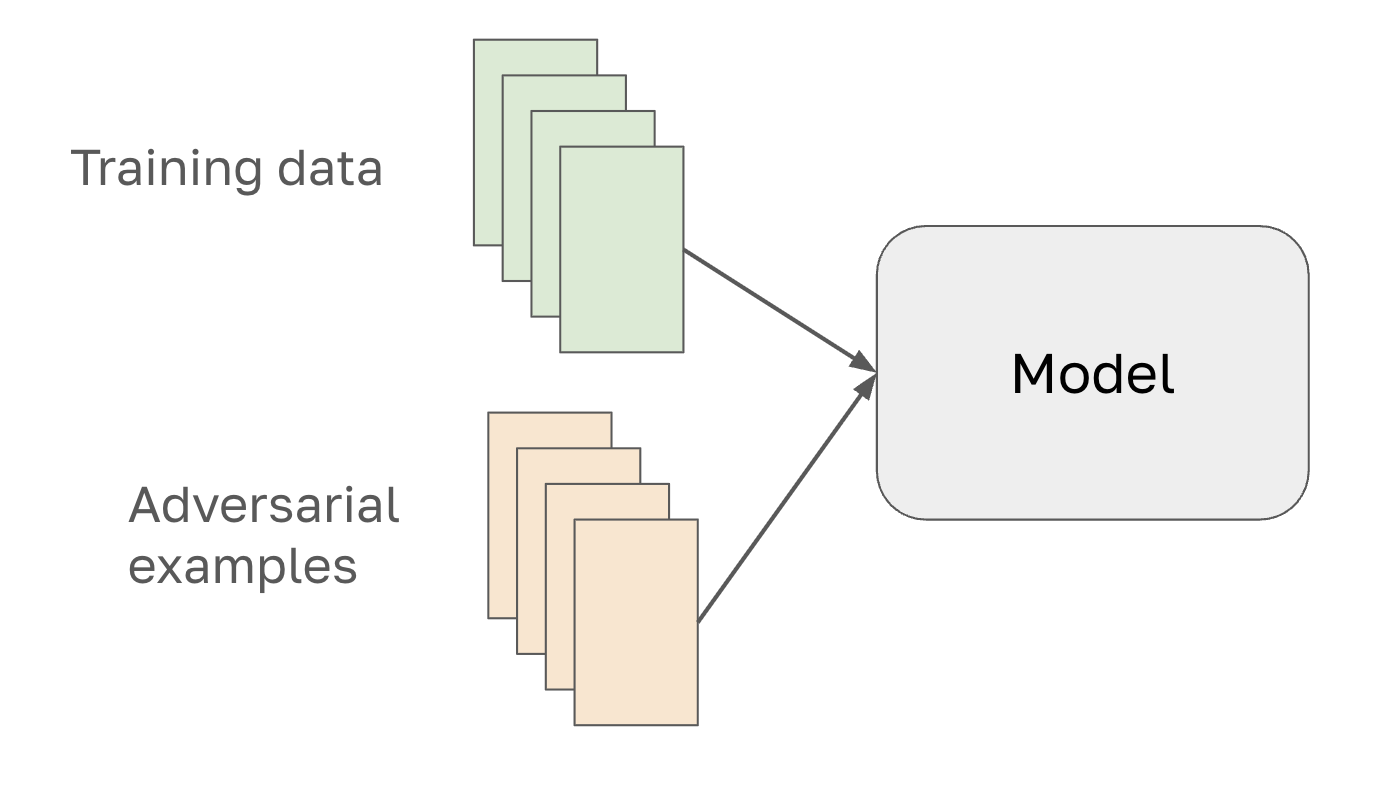
Mitigation 1: Adversarial training
Generate adversarial examples (using a known attack method like FGSM or PGD), include them in your training data, and retrain. The model becomes more robust to that specific attack. This is a cat-and-mouse game — robust to one attack does not imply robust to all attacks — but it's a meaningful improvement and is standard practice in safety-critical deployments.
Mitigation 2: Input sanitization
Apply preprocessing, quality assessment, or content filtering on the conditioning inputs before they reach the model. If a user is uploading an image as conditioning, run it through a check first. This adds latency but adds a meaningful security layer. Combine with rate limiting, anomaly detection on inputs, and logging of conditioning inputs for audit.
Choose an input type to see how it moves through the sanitization pipeline before reaching the model. Each check adds latency — but catches a different class of threat.
Select input type
A normal user photo — correct format, good quality, no manipulation.
The latency trade-off
For clean image, this pipeline adds approximately 253ms before the model sees the input. That's the cost of the security layer — meaningful, but small compared to model inference time (often 500ms–5s). Blocking early means cheaper rejections: a bad input caught at format validation never reaches the expensive perturbation detector.
Select an input type and run the pipeline to see which checks catch it, how much latency each layer adds, and whether the input reaches the model.
Adversarial training is a common mitigation for adversarial attacks on generative models. What is the key limitation of this approach?
A hospital wants to deploy a VAE-based anomaly detection system that flags unusual MRI scans for radiologist review. Walk through at least three of the challenges covered here in Chapter 7 and explain how you would mitigate each one in this specific deployment context.