Other Segmentation Architectures
U-Net is not the only segmentation architecture, and practitioners should be aware of the landscape:
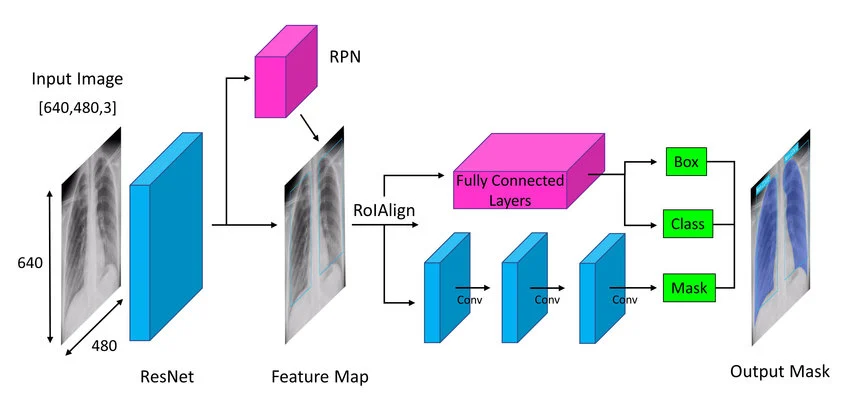
- Mask R-CNN — Extends Faster R-CNN to output instance segmentation masks. Adds a parallel mask prediction branch to the classification and bounding box heads. State-of-the-art for instance segmentation. If you need to distinguish between individual objects of the same class, this is your starting point.
- DeepLabV3 — Uses atrous (dilated) convolutions to capture multi-scale context without reducing spatial resolution. Combines these with "atrous spatial pyramid pooling" to aggregate features at multiple scales. Strong performer on semantic segmentation benchmarks.
- PSPNet (Pyramid Scene Parsing Network) — Applies pooling at multiple scales to capture global context, then concatenates the results. Particularly effective on complex urban scenes where global context matters for disambiguation.
✦
Choosing a Segmentation Architecture
- Medical / scientific imaging — Start with U-Net. It was designed for this context and has the most domain-specific literature behind it.
- Need to count or distinguish individual objects — Use Mask R-CNN for instance segmentation.
- Outdoor scenes, autonomous driving — DeepLabV3 or PSPNet, which handle complex multi-scale scenes well.
💭Reflection
A wildlife conservation team wants to count individual sea turtles in aerial photographs and measure the size of each one. What segmentation approach would you use, and why does it matter that they want individual measurements rather than just a class label?